Chapter 6 Comparing two means
This chapter is about inferential tests that compare two means, each with a normal distribution of errors. It follows the main textbook (Navarro & Foxcroft, 2019, Chapter 11). Think of it this way: If you have a single outcome variable, but both men and women contributed to the responses on that outcome variable, then you can split that outcome variable into two means: one for the women, and one for the men. Now you can compare these two means (with an independent samples t-test).
In fact, there are four different situations when you might compare two means:
- When you have collected only one sample (you can’t split your outcome into two), but you have information about a population that you’d like to compare that sample to.
- In the case where you have access to both a known population mean and standard deviation (known population SAT scores from the College Board), you can use a one-sample z-test
- In the he case where you have access to the population mean, but not the population standard deviation (just like above, but more much more likely to be your case), you use what’s called a one-sample t-test
- In the case where you have access to both a known population mean and standard deviation (known population SAT scores from the College Board), you can use a one-sample z-test
- When you do have two samples that you can split your outcome variable by.
- In the case where the two samples do not consist of the same people (e.g., men vs. women), you can use an independent-samples t-test
- In the case where you have the same group of people sampled twice (e.g., time 1 vs. time 2), you can use a dependent-samples t-test, also known as a paired t-test.60
- In the case where the two samples do not consist of the same people (e.g., men vs. women), you can use an independent-samples t-test
We will skip the one-sample z-test since it is unrealistic to begin with (See Navarro & Foxcroft, 2019, sec. 11.1). In fact, we will also skip one-sample t-test for the sake of brevity. The independent samples, and paired-samples t-tests are much more common in practice anyway.
6.1 The independent-samples t-test
Carrying out independent-samples t-tests is covered in your main textbook (Navarro & Foxcroft, 2019, sec. 11.3).
In this test, we are interested in whether two groups comprising independent observations differ with each on a single, continuous outcome variable. The standard equation for this is called Student’s t.61
Of course, you do not need to calculate Student’s t, or any other statistical equation in jamovi; the software does it for you… which is the sine qua non of statistical software in general. So let’s get to that.
6.1.1 Basic: Dr. Harpo’s statistics class
For a basic introduction to how to do a t-test in jamovi, we replicated the the example from the textbook in Section 11.3. It’s the Harpo data again, which you already worked on in this lab manual in Section 4.2 under visualizing data with boxplots.
6.1.1.1 Obtaining the data
To follow along yourself, you can open that file (if you saved it), or the one in the module from Navarro & Foxcroft (2019): (\(\equiv\)) > File > Data Library > learning statistics with jamovi > Harpo.omv. Make sure to modify grade to be continuous (if necessary) and tutor to have two levels: Anastasia and Bernadette (if necessary).
6.1.1.2 Implementing the procedure
We clicked the Analyses tab and selected T-Tests. We slid grade into the Dependent Variables box, and tutor into the Grouping Variable box. Under Tests we checked Student's (for the traditional t-test), as well as the “alternative” test, Welch's, which actually turns out to be better in most cases (and less confusing!). The research hypothesis (see Chapter 9 of Navarro & Foxcroft, 2019) is non-directional, so we left Group 1 \(\ne\) Group 2 (the default) checked under Hypothesis. As for Additional Statistics, we checked Effect size, Descriptives, and Descriptives plots.
The top two options under Assumption Checks, can really be addressed before you get to the inferential-test stage, so we chose not to do them here. However, the Equality of variances option is an interesting case in jamovi. jamovi is “smart”,62 so IF you check Student's without checking Welch's, then jamovi will add a footnote about the test for equality of variances (Levene's test). This is because using the Student’s t-test is only appropriate if you have equality of variances across the two conditions. To pass Levene’s test, your p-value must be greater than .05 (not less, like in the regular inferential tests). This is because the null hypothesis for equality of variances is that the variances are equal. So you want to fail to reject that particular null hypothesis. This is counter-intuitive once you have a handle on null-hypothesis significance testing, but you’ll get used to it. Many assumption checks work the opposite way from the inferential tests.
But you might also notice (if you play around a bit) that if you also check Welch's, then Levene’s test disappears from the footnote in the output. You have to ask for it specifically (at the lower right). This is because the (smart) programmers at jamovi knew that if you also selected Welch's that you really didn’t need the test for equality of variances in the first place since the test is irrelevant for Welch’s t-test (which internally corrects for inequality of variances). But you can still ask for it by checking the box for it at the lower right. We did that here. We went one step further and un-checked Student's just to simplify the output.
Thus, the options shown below in Figure 6.1 should be more than enough to make educated decisions about the t-test.
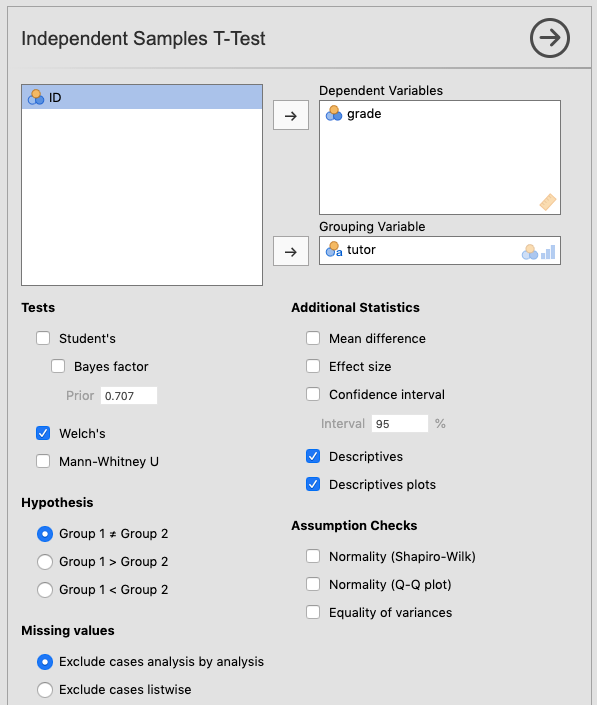
Figure 6.1: Parameter settings for the independent samples t-test using the Harpo data from Navarro & Foxcroft (2019).
If you’re following along, you should see something like the following as output:63
INDEPENDENT SAMPLES T-TEST
Independent Samples T-Test
────────────────────────────────────────────────────────────
Statistic df p
────────────────────────────────────────────────────────────
grade Welch's t 2.034187 23.02481 0.0536100
────────────────────────────────────────────────────────────
Note. Hₐ μ <sub>Anastasia</sub> ≠
μ <sub>Bernadette</sub>
Group Descriptives
─────────────────────────────────────────────────────────────────────────────
Group N Mean Median SD SE
─────────────────────────────────────────────────────────────────────────────
grade Anastasia 15 74.53333 76.00000 8.998942 2.323517
Bernadette 18 69.05556 69.00000 5.774918 1.361161
───────────────────────────────────────────────────────────────────────────── 
6.1.1.3 Interpreting the output
Here you can see that the difference in grades between Anastasia’s and Bernadette’s tutoring groups are marginally significant64 using Welch’s t-test, which is the appropriate choice here.
6.1.1.4 Reporting the output
As far as a write-up is concerned, this is how it might come out:
The students in the group that Anastasia tutored scored a little bit higher (M = 74.5, SD = 9, n = 15) than those of Bernadette (M = 69.1, SD = 5.77, n = 18). This difference in means was marginally significant, Welch’s t(23) = 2.03, p = 054, with a medium-strong effect size (d = .74).
(For a guide on how to report t-tests, see section 12.4.1.3.2)
6.1.2 Advanced 1: The conspiracy data
We’re going to use another online open data set. This one is more involved, but fun. It is called the Generic Conspiracist Beliefs Scale (Brotherton et al., 2013). If you like, you can take the survey yourself here. The online version is strictly for fun.
6.1.2.1 Obtaining the data
This is an online survey designed to tap into the belief in generic conspiracy theories (there are 15 generic conspiracies covered, which were distilled down, mathematically,65 from 75). You can see these questions here, or in the Appendix of Brotherton et al. (2013). Responses to these question were on a Likert Scale, ranging from 1 (Definitely not true) to 5 (Definitely true).
{kind=link}
The data (data.csv) and codebook (codebook.txt) can be found online here as a .zip file, or, for Texas A&M students in PSYC 301, on Canvas under Lab: Lab manual data sets > TwoMeans_GCBS (a folder containing the two files). Feel free to follow along with how we analyzed this data.
In this case, as we saw before, the researchers indicated non-responses with a 0. Zero, then, is the number that represents missing values. So before we imported the data, we put 0 (i.e., zero, with no quotes) into the Default missings box under preferences (\(\vdots\)).
6.1.2.2 Adjusting the data
Once the data was imported (as we did back in Sections 2.3 and 2.8.3), we changed some variable names with some help from the codebook. We also adjusted the variable types. We chose variable Q3 (Secret organizations communicate with extraterrestrials, but keep this fact from the public) as our outcome variable (We called it Comm.Wth.Exts just to save space in the jamovi output). The changes are depicted below in 6.2.
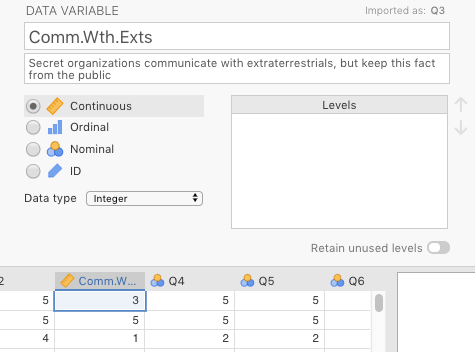
Figure 6.2: Changes made in jamovi to the variable Q3 from Brotherton et al. (2013).
We chose voted (Have you voted in a national election in the past year?) as our two-level predictor variable. We changed the name to Voted.In.Past.Year. The change we made to it is shown in Figure 6.3 below.
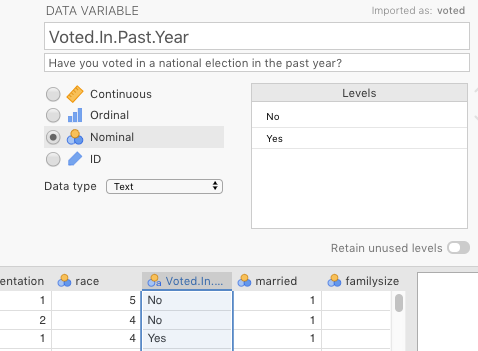
Figure 6.3: Changes made in jamovi to the variable voted from Brotherton et al. (2013).
If we wanted to analyze any other variables, we would need to adjust those too. But there is no reason to do so in this manual, though you are welcome to play with the data yourself.
6.1.2.3 Implementing the procedure
We used the same settings as above in Figure 6.1, except that we kept the Student’s option checked, and we also checked Equality of variances under the heading Assumption Checks.
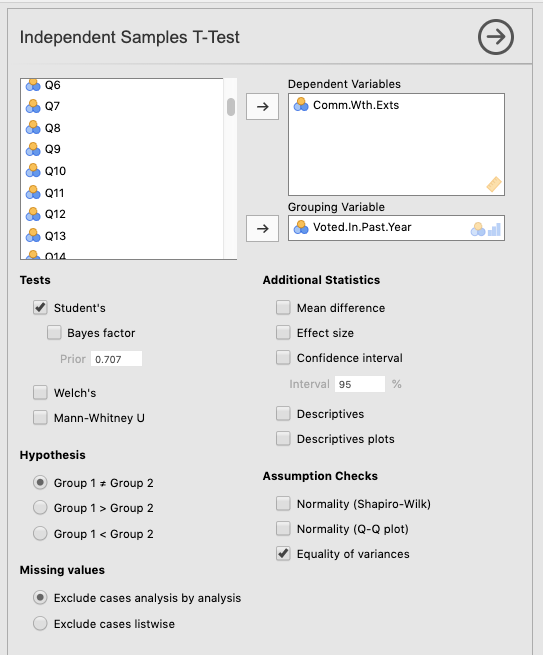
Figure 6.4: Setting the parameters for a t-test on variables from Brotherton et al. (2013).
6.1.2.4 Interpreting the output
The output below is what you should see in jamovi if you had only checked Student’s t-test. Notice the footnote telling you that you can’t really use Student’s t-test. We also explicitly included the more detailed output for Levene’s test below the t-test output. There you can see that the failure of this test is a pretty spectacular failure with an F value of 35.9 (trust us, this is a large F value). We’ll get to what this all means when we analyze the final output.
INDEPENDENT SAMPLES T-TEST
Independent Samples T-Test
───────────────────────────────────────────────────────────────────────
Statistic df p
───────────────────────────────────────────────────────────────────────
Comm.Wth.Exts Student's t 5.035711 ᵃ 2462.000 0.0000005
───────────────────────────────────────────────────────────────────────
Note. Hₐ μ <sub>No</sub> ≠ μ <sub>Yes</sub>
ᵃ Levene's test is significant (p < .05), suggesting a violation
of the assumption of equal variances
ASSUMPTIONS
Homogeneity of Variances Test (Levene's)
─────────────────────────────────────────────────────────
F df df2 p
─────────────────────────────────────────────────────────
Comm.Wth.Exts 35.94557 1 2462 < .0000001
─────────────────────────────────────────────────────────
Note. A low p-value suggests a violation of the
assumption of equal variancesIn contrast, if you had only checked Welch’s66, then the output is much simpler, and safer to go with. You can see it in the output below, where we have also included descriptive statistics and plots.
INDEPENDENT SAMPLES T-TEST
Independent Samples T-Test
────────────────────────────────────────────────────────────────────────────────────────────────
Statistic df p Effect Size
────────────────────────────────────────────────────────────────────────────────────────────────
Comm.Wth.Exts Welch's t 5.265362 1741.577 0.0000002 Cohen's d 0.2220098
────────────────────────────────────────────────────────────────────────────────────────────────
Note. Hₐ μ <sub>No</sub> ≠ μ <sub>Yes</sub>
Group Descriptives
────────────────────────────────────────────────────────────────────────────────────
Group N Mean Median SD SE
────────────────────────────────────────────────────────────────────────────────────
Comm.Wth.Exts No 1672 2.147727 1.000000 1.429473 0.03495891
Yes 792 1.848485 1.000000 1.261016 0.04480826
──────────────────────────────────────────────────────────────────────────────────── 
Clearly, the effect is significant. But how do we interpret that? Well it turns out that with t-tests it’s very simple in the case of a significant effect: The mean that is greater is significantly greater than the other, and vice-versa.
But there’s a bigger problem. This is something that would have been caught beforehand if looking specifically at Descriptives (as we did in Chapter 3). But you can see it in two places here: 1) in the table of Descriptives that we asked for; and especially in 2) in the Descriptives plots.
Do you see it?
Look at the means vs. the medians. The numbers are give explicitly in the table, but the dot plot really shows you what’s happening. The means are plotted as circles flanked by confidence intervals.67 They look quite normal. However, the medians (represented as squares) are both at the bottom. This suggests, as you might expect, that the vast majority of respondents do not believe this kind of conspiracy theory. The distribution must be massively skewed to the right.
The best way to see this is with a violin plot with the Data: Jittered option checked (see Section 4.3).
DESCRIPTIVES
Descriptives
─────────────────────────────────────────────────────────────
Voted.In.Past.Year Comm.Wth.Exts
─────────────────────────────────────────────────────────────
N No 1672
Yes 792
Standard deviation No 1.429473
Yes 1.261016
───────────────────────────────────────────────────────────── 
Clearly, the distributions are very similar to each other, but they are heavily skewed positively (Remember, violin plots are like histograms [density plots, really] tilted 90 degrees counterclockwise, and then mirrored). The “violins” should be fat in the middle and narrow at the extremes. Instead, both violin plots look like narrow vases with wide bases, where the vast majority of the responses are 1, at the lower end of the scale (which is on the y-axis now, not on the left-hand side of the x-axis, as is true for histograms).
The t-test gave us a significant result, but it is not an appropriate test at all.
You might be asking yourself why we chose such an inappropriate data set while introducing you to the t-test. Consider this an extreme example of why it is important to check statistical assumptions. Notice that if you just look at the results of the t-test without looking at the distribution of the variables or other diagnostics, you could easily come to the conclusion that the t-test showed us significant differences. This is where the following quotation is appropriate:
“There are three kinds of lies: lies, damned lies, and statistics”
— Mark Twain purportedly quoting Benjamin Disraeli (but see here)
Of course, the quote is both true and false. It is false because statistics cannot in and of themselves lie. After all, they’re not human, and they tell you exactly what you ask them to tell you (perfect truth-tellers in fact). But humans can lie (or more commonly, tell half-truths) with statistics. That’s how the quote is true in this case.
6.1.2.5 Reporting the output
Just as you saw with the chi-square analyses in Chapter 5, the APA reporting guidelines follow an almost universal pattern for statistical tests, with the following eight elements appearing left-to-right in order:
- a letter (in italics) representing the test statistic used
- parentheses that enclose the degrees of freedom
- an equals sign
- the obtained value of the test statistic
- a comma
- the letter p in italics
- one of three symbols: =, <, or >
- a p-value
“An independent-samples t-test was carried out between people who had voted in the previous year and those who had not on degree of agreement with a conspiracy theory in which secret organizations are concealing from the public their contact with aliens. Those who had voted showed significantly less agreement with the conspiracy statement (M = 1.85, SD = 1.26, n = 792) than those who had not voted (M = 2.15, SD = 1.43, n = 1,672) according to Welch’s t(1742) = 5.27, p < .001. The effect size was somewhat small (d = 0.21).”
For a guide on how to report t-tests specifically, as above, see Section 12.4.1.3.2.
6.1.2.6 Alternative analysis of conspiracy data
Briefly, to deal with this particular problem, one could carry out chi-square analysis. It’s a bit cruder, since you lose a good deal of information, but it will do the trick. First, we would need to compute a new variable in order to do a chi-square analysis as in the last chapter in this manual, which is also in Chapter 10 of Navarro & Foxcroft (2019).
6.1.2.6.1 Recoding the Likert item
We created a new two-level factor from the original Likert item. This was done in jamovi through the Data tab. We just clicked Compute from there. This automatically inserted a new column, but without any values. We gave the variable a new name (Count.Comm.Wth.Exts), and inserted the following IF-THEN-ELSE statement into the function box:
“IF(Comm.Wth.Exts==1,”Totally Disagree”,“Do NOT Totally Disagree”)”
See Figure 6.5 below.
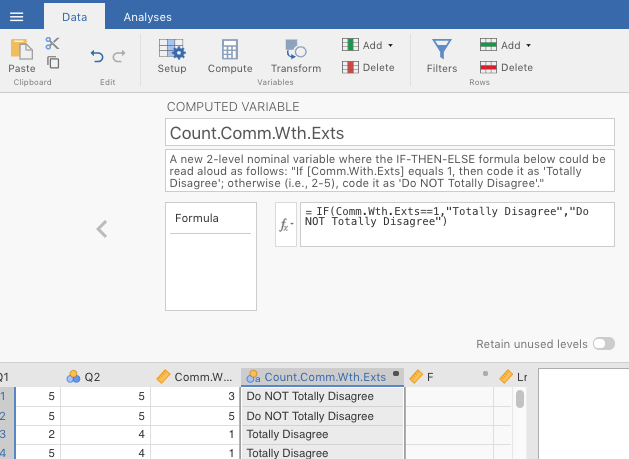
Figure 6.5: Computing a new, 2-level nominal variable based on an old continuous variable using an IF-THEN-ELSE function in jamovi.
The end result was a new categorical variable with two levels.68
6.1.2.6.2 Doing a chi-square analysis
Next we did an independent samples chi-square test of association (see last chapter). The results are displayed in the table below.
CONTINGENCY TABLES
Contingency Tables
─────────────────────────────────────────────────────────────────────────────────────
Count.Comm.Wth.Exts No Yes Total
─────────────────────────────────────────────────────────────────────────────────────
Do NOT Totally Disagree Observed 805 303 1108
Expected 751.8571 356.1429 1108.000
% within column 48.14593 38.25758 44.96753
Totally Disagree Observed 867 489 1356
Expected 920.1429 435.8571 1356.000
% within column 51.85407 61.74242 55.03247
Total Observed 1672 792 2464
Expected 1672.0000 792.0000 2464.000
% within column 100.00000 100.00000 100.00000
─────────────────────────────────────────────────────────────────────────────────────
χ² Tests
───────────────────────────────────────────────────────────
Value df p
───────────────────────────────────────────────────────────
χ² continuity correction 20.83724 1 0.0000050
N 2464
───────────────────────────────────────────────────────────
Nominal
─────────────────────────────────
Value
─────────────────────────────────
Phi-coefficient 0.09283359
Cramer's V 0.09283359
───────────────────────────────── The chi-square test was significant. Looking at the contingency table, one can see the following. Among those who did not vote, the expected number of people who totally disagreed with the conspiracy theory was lower (867) than expected (920), whereas among those who did vote, the number of people who totally disagreed was higher (489) than expected (436). Also, among those who did not vote, there was about a 50/50 split between absolutely disagreeing and not-totally disagreeing with the conspiracy theory. In contrast, among those who did vote, those who disagreed outnumbered those who didn’t totally disagree by about 5-to-3.
This test is not as potentially informative as having the convenience of 1-5 Likert scale. However, it is more appropriate in this case. You can trust these results more.69
6.1.2.6.3 Reporting the alternative output
(See section 12.4.1.3.2 for a guide on how to report chi-square analyses in APA format)
What follows is more legitimate report, namely, that of the chi-square analysis:
“An independent-samples Chi-square test of association was calculating comparing the relative frequencies of voters vs. non-voters in their propensity to agree with a conspiracy-theory statement concerning secret societies concealing their contact with aliens. There was a significant interaction, \(\chi\)2(1, N = 2464) = 20.8, p < .001. The effect size was quite small (\(\phi\) = .09). There were slightly fewer-than-expected voters who agreed with the statement, whereas there were slightly more-than-expected non-voters who agreed with the statement.”
6.1.3 Advanced 2: Spoken vs. written pitches
You will be working on a real data set. The description of the study is below, followed by the relevant tasks you need to carry out, as well as some useful information to get you started.
6.1.3.1 Study description
The following activity is a partially altered version of one developed by McIntyre (2016).
Imagine you were a job candidate trying to pitch your skills to a potential employer. Would you be more likely to get the job after giving a short speech describing your skills, or after writing a short speech and having a potential employer read those words? That was the question raised by a couple of researchers at the University of Chicago. The authors predicted that a person’s speech (i.e., vocal tone, cadence, and pitch) communicates information about their intellect better than their written words (even if they are the same words as in the speech).
To examine this possibility, the authors randomly assigned 39 professional recruiters for Fortune 500 companies to one of two conditions. In the audio condition, participants listened to audio recordings of a job candidate’s spoken job pitch. In the transcript condition, participants read a transcription of the job candidate’s pitch. After hearing or reading the pitch, the participants rated the job candidates on three dimensions: intelligence, competence, and thoughtfulness. These ratings were then averaged to create a single measure of the job candidate’s intellect, with higher scores indicating the recruiters rated the candidates as higher in intellect. The participants also rated their overall impression of the job candidate (a composite of two items measuring positive and negative impressions). Finally, the participants indicated how likely they would be to recommend hiring the job candidate (0 - not at all likely, 10 - extremely likely).
6.1.3.2 Your tasks
- Start jamovi.
- Import the data file in Canvas called
TwoMeans_SpokeWrit.csv.
Import: Default missings you should type in ““, as displayed below in Figure 6.6.
Figure 6.6: Setting Default missings to blanks (““) in jamovi.
- Explore the data file. Note, you will not analyze all of these variables. Try to find the variables that are relevant to the study description above. Modify them if necessary.
- Save it as .omv file with the following name: “SpokeWritExercise_YOURLASTNAME_YOUR FIRSTNAME.omv” (where the elements in uppercase are replaced with your last and first name, respectively).
- You first want compare participants in the audio condition to participants in the
transcriptcondition on theIntellect_Ratingvariable. Which type of analysis is appropriate, given the design described above?
- Next compare participants in the
audiocondition to participants in thetranscriptcondition on theImpression_Ratingvariable.
- Finally, compare participants in the
audiocondition to participants in thetranscriptcondition on theHire_Ratingvariable.
- Prepare an APA-style results paragraph describing the results of the analyses performed above.
6.2 The paired-samples t-test
Paired samples t-tests are used when you have a single outcome variable, but the two groups that you are splitting the outcome variable by consist of the same people (or sometimes, different people who are highly matched on key variables). The key here is that the concept that splits the two means must result in correlated values, meaning that the value for one of the “levels” gives you a good idea of what the value for the other “level” is.
You might be asking yourself why we used the term concept instead of variable (after all, you split your outcome variable by another two-level predictor in the case of the independent samples t-test; don’t you do the same thing here?). You need not worry very much; we’re actually just highlighting something about the data set that is typically used for this kind of analysis. In a traditional paired samples t-test, the two levels of the predictor variable are represented as two separate columns.70 So there technically is no variable in the data set, per se, that splits the variable into its two levels. You have to understand that your data set has that structure. When you run the analysis in jamovi, you will need to select two different columns corresponding to those two levels.71 You will see this shortly.
6.2.1 Basic: The Chico data
For the basic paired-samples t-test we are going to analyze the sample data provided by Navarro & Foxcroft (2019) in the data set Chico.omv. To find this data set, simply go to (\(\equiv\)) > File > Open > Data Library > Chico. The data should look like the table below.
| id | grade_test1 | grade_test2 |
|---|---|---|
| student1 | 42.9 | 44.6 |
| student2 | 51.8 | 54.0 |
| student3 | 71.7 | 72.3 |
| student4 | 51.6 | 53.4 |
| student5 | 63.5 | 63.8 |
| student6 | 58.0 | 59.3 |
| student7 | 59.8 | 60.8 |
| student8 | 50.8 | 51.6 |
| student9 | 62.5 | 64.3 |
| student10 | 61.9 | 63.2 |
| student11 | 50.4 | 51.8 |
| student12 | 52.6 | 52.2 |
| student13 | 63.0 | 63.0 |
| student14 | 58.3 | 60.5 |
| student15 | 53.3 | 57.1 |
| student16 | 58.7 | 60.1 |
| student17 | 50.1 | 51.7 |
| student18 | 64.2 | 65.6 |
| student19 | 57.4 | 58.3 |
| student20 | 57.1 | 60.1 |
Descriptives of the data should come out as follows:
DESCRIPTIVES
Descriptives
────────────────────────────────────────────────────
grade_test1 grade_test2
────────────────────────────────────────────────────
N 20 20
Mean 56.98000 58.38500
Standard deviation 6.616137 6.405612
──────────────────────────────────────────────────── 6.2.1.1 Implementing the procedure
To get a paired-samples t-test, Go to Analyses > T-Tests tabs. Then slide grade_test2 over to the Paired Variables box. It should end up on the left-hand column of that box. Then slide grade_test1 over. This variable should end up in the right-hand column.72 Additionally, make sure that Student’s is checked, along with Effect size and Descriptive plots. Figure 6.7 below shows what you should see after doing all this.
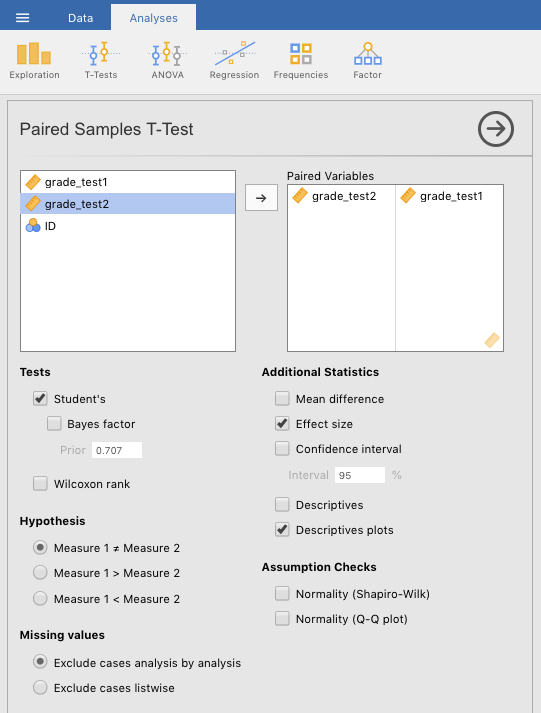
Figure 6.7: Setting the parameters for a paired-samples t-test on a simulation of the Chico data from Navarro & Foxcroft (2019).
The output from this procedure can be seen below.
PAIRED SAMPLES T-TEST
Paired Samples T-Test
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
statistic df p Effect Size
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
grade_test2 grade_test1 Student's t 6.475436 19.00000 0.0000033 Cohen's d 1.447952
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
Note. Hₐ μ <sub>Measure 1 - Measure 2</sub> ≠ 0
6.2.1.2 Interpreting
The test was clearly statistically significant with p less than .001, with Student’s t at 6.48 (19 degrees of freedom). From the graph, it looks like grades at time of test 2 were significantly greater than at time of test 1.
But there is one issue here that might get overlooked in the graph. Normally, one can use confidence intervals to judge significance. Specifically, when confidence intervals do not overlap, or overlap only a little, one can hazard a guess that the difference is significant. This was evident in our basic analysis of the independent-samples t-test above (Section 6.1.1), the Dr. Harpo data. Note that the confidence intervals cross just a little, and the p-value is borderline significant.
However, this trick that compares confidence intervals only works with independent-samples (or between-subjects tests). When the comparisons are paired (or repeated measures), confidence intervals do not work so well because they over-estimate the error. That is, they are too wide. Notice here that the confidence intervals cross each other a lot, yet the effect is significant. This is common in paired-samples (or repeated-measures) data.
6.2.1.3 Reporting
What follows is how one might report this analysis:
“The 20 students in Dr. Chico’s class scored a little bit higher on the second exam (M = 58.4, SD = 6.41) than they did on the first exam (M = 57.0, SD = 6.62). This difference in means was highly significant according to a paired t-test, t(19) = 6.48, p < .001, with a strong effect size (d = 1.45).”
6.2.2 Advanced 1: Randomly generated Chico data
For the first advanced, paired t-test we are just going to add a small twist. We are going to modify the data so that you create the data yourself, as you may have tried in Section 2.5.1.2.
6.2.2.1 “Replicating” the data
To start, for the purpose of illustration,73 we will replicate the original means and standard deviations of the Chico.omv data set with a different set of data points. Begin by opening a new file in jamovi by clicking (\(\equiv\)) > New.
Select the default variables (A through C) and delete them using Delete under the Data tab.
Double-click a blank variable (at the header, or top row) and choose NEW DATA VARIABLE. Give it the name ID, and make it an ID variable type. See Figure 6.8
Figure 6.8: Creating a new ID variable.
Then, double-click another blank column header, but this time choose NEW COMPUTED VARIABLE. Name it grade_test1. In the original, sample data set, the mean of this variable is 57.0, with a standard deviation of 6.62. So in the formula box (\(f_{x}\)), type in the following formula: =NORM(57,6.62), then press
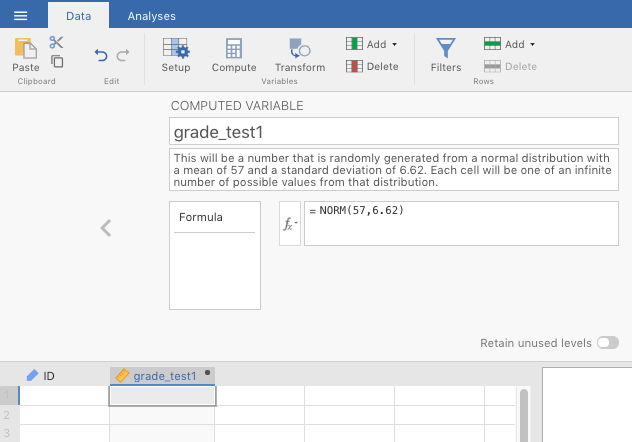
Figure 6.9: Step one of creading a new computed variable, consisting of observations drawn randomly from an infinite number of observations comprising a normal distribution with a mean of 57 and a standard deviation of 6.62.
Now, go back to the spreadsheet and start entering values into the ID cells. Start with the top left, and enter “1” (without quotation marks). You’ll see the two computed variables automatically fill up with “random” numbers. Do this for 20 rows, with a different number for each row of ID (the easiest is to use the numbers 1-20, of course, and jamovi will not think that they’re numbers since you set it as an ID variable type). In Figure 6.10 below, you can see that it’s possible to skip rows on the ID variable. The ID variable is not that important for our purposes anyway.
Figure 6.10: Filling in rows in the new, computed variable. Note the ability to skip rows on the ID variable.
See the table below for OUR data (the odds are astronomically low that you would have the same values since they were generated randomly).
| ID | grade_test1 | grade_test2 |
|---|---|---|
| 1 | 55.43 | 49.66 |
| 2 | 56.09 | 62.77 |
| 3 | 53.42 | 57.23 |
| 4 | 71.30 | 50.85 |
| 5 | 62.74 | 61.41 |
| 6 | 44.42 | 56.21 |
| 7 | 45.25 | 59.88 |
| 8 | 51.18 | 49.55 |
| 9 | 61.99 | 52.21 |
| 10 | 44.13 | 63.12 |
| 11 | 50.94 | 61.10 |
| 12 | 62.97 | 67.07 |
| 13 | 58.07 | 59.10 |
| 14 | 57.39 | 58.84 |
| 15 | 58.00 | 55.48 |
| 16 | 55.43 | 62.91 |
| 17 | 57.31 | 52.78 |
| 18 | 55.74 | 53.81 |
| 19 | 59.66 | 58.74 |
| 20 | 54.64 | 49.98 |
Now you should do descriptives on your data as you did in Sections 3.2.1 and 3.4. Be sure to click standard deviation. The table below shows the relevant descriptives for our data (again, yours will be different).
DESCRIPTIVES
Descriptives
────────────────────────────────────────────────────
grade_test1 grade_test2
────────────────────────────────────────────────────
N 20 20
Mean 55.80603 57.13532
Standard deviation 6.638070 5.192624
──────────────────────────────────────────────────── You might be shocked to notice that the means and standard deviations are not exactly the same as they are in the original Chico.omv file. This is because the =NORM() function does not replicate the data set per se. Rather, it draws values at random from a theoretical, normal distribution defined by your parameters (e.g., a mean of 57 and a standard deviation of 6.62), and those theoretical distributions consist of an infinite number of observations to draw from. It also follows that the more observations you add here, the closer you will get to the means and standard deviations of the original settings.
We are now ready to analyze the data using a paired-samples t-test. We will show you the results of with our randomly generated data, but yours will necessarily be different.
6.2.2.2 Implementing the procedure
You can now run the same test as above in section 6.2.1 and Figure 6.7. The output from this procedure can be seen below.
PAIRED SAMPLES T-TEST
Paired Samples T-Test
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
statistic df p Effect Size
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
grade_test2 grade_test1 Student's t 0.6643604 19.00000 0.5144424 Cohen's d 0.1485555
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
Note. Hₐ μ <sub>Measure 1 - Measure 2</sub> ≠ 0
6.2.2.3 Interpreting the output
Our data is not even close to significant, with a p-value approaching 0.5 (recall, our alpha level is .05, not .5). This contrasts a great deal with the original Chico data from Navarro & Foxcroft (2019). Their data was presumably not randomly generated, but rather artificially constructed to show a particular pattern, namely, scores at time 2 always being higher than scores at time 1 (this was the research hypothesis, in fact).
You might expect this, as the two grades from each student are supposed to be correlated with each other. Correlated in this case means that, given one value for a student, you can make a pretty good prediction about their other value. Or specifically, given their score on test 1, you can make a reasonable guess that their score on test 2 will be higher. This is why we do paired-samples t-tests in fact.
To determine if this was, in fact, the case, we subtracted the scores for time 1 from the scores for time 2, and called the new variable DIFF. We did this for both data sets. If students are generally doing better the 2nd time, then you should see mostly positive difference scores. This is exactly what we see for the original data set below.
| id | grade_test1 | grade_test2 | DIFF |
|---|---|---|---|
| student1 | 42.9 | 44.6 | 1.7 |
| student2 | 51.8 | 54.0 | 2.2 |
| student3 | 71.7 | 72.3 | 0.6 |
| student4 | 51.6 | 53.4 | 1.8 |
| student5 | 63.5 | 63.8 | 0.3 |
| student6 | 58.0 | 59.3 | 1.3 |
| student7 | 59.8 | 60.8 | 1.0 |
| student8 | 50.8 | 51.6 | 0.8 |
| student9 | 62.5 | 64.3 | 1.8 |
| student10 | 61.9 | 63.2 | 1.3 |
| student11 | 50.4 | 51.8 | 1.4 |
| student12 | 52.6 | 52.2 | -0.4 |
| student13 | 63.0 | 63.0 | 0.0 |
| student14 | 58.3 | 60.5 | 2.2 |
| student15 | 53.3 | 57.1 | 3.8 |
| student16 | 58.7 | 60.1 | 1.4 |
| student17 | 50.1 | 51.7 | 1.6 |
| student18 | 64.2 | 65.6 | 1.4 |
| student19 | 57.4 | 58.3 | 0.9 |
| student20 | 57.1 | 60.1 | 3.0 |
We can do the same with our randomly generated data.
| ID | grade_test1 | grade_test2 | DIFF |
|---|---|---|---|
| 1 | 55.43 | 49.66 | -5.78 |
| 2 | 56.09 | 62.77 | 6.68 |
| 3 | 53.42 | 57.23 | 3.81 |
| 4 | 71.30 | 50.85 | -20.45 |
| 5 | 62.74 | 61.41 | -1.33 |
| 6 | 44.42 | 56.21 | 11.79 |
| 7 | 45.25 | 59.88 | 14.63 |
| 8 | 51.18 | 49.55 | -1.63 |
| 9 | 61.99 | 52.21 | -9.78 |
| 10 | 44.13 | 63.12 | 18.99 |
| 11 | 50.94 | 61.10 | 10.16 |
| 12 | 62.97 | 67.07 | 4.09 |
| 13 | 58.07 | 59.10 | 1.02 |
| 14 | 57.39 | 58.84 | 1.44 |
| 15 | 58.00 | 55.48 | -2.52 |
| 16 | 55.43 | 62.91 | 7.48 |
| 17 | 57.31 | 52.78 | -4.53 |
| 18 | 55.74 | 53.81 | -1.92 |
| 19 | 59.66 | 58.74 | -0.92 |
| 20 | 54.64 | 49.98 | -4.66 |
It is clear from this second table that these scores are uncorrelated with each other. Some values are higher during the 2nd test, whereas others a lower. The underlying pattern is random, except that the values for time 2 are slightly higher, on average than the values for time 1. That makes sense because jamovi calculated random values for each variable, without any kind of underlying correlation between any two values for one student (i.e., some did better on the 2nd test; some did worse, in about equal). Apologies for leading you up the garden path. But we needed to illustrate that two randomly generated variables are not necessarily correlated (and probably won’t be).
It turns out that there was a way to get time 2 correlated with time 1, with the former being slightly greater than the latter. See below.
In the NEW VARIABLE formula for time 2, we should not have entered “=NORM(58.4,6.41)” for grade_test2 (see Figure 6.9) but rather “=grade_test1 + NORM(1.4, 0.97)” (which correspond the actual mean and standard deviation of the difference scores in the original data set). This new formula can be read as follows:
“take
grade_test1and add to it a value randomly drawn from a distribution (of infinite values) with a mean of 1.4, and a standard deviation of 0.97.”
This will generate correlated values within observations. You can see this in the table below if you look at the DIFF scores.
| ID | grade_test1 | grade_test2 | DIFF |
|---|---|---|---|
| 1 | 55.43 | 58.13 | 2.69 |
| 2 | 56.09 | 56.96 | 0.87 |
| 3 | 53.42 | 57.15 | 3.73 |
| 4 | 71.30 | 73.72 | 2.41 |
| 5 | 62.74 | 64.67 | 1.93 |
| 6 | 44.42 | 45.08 | 0.65 |
| 7 | 45.25 | 47.52 | 2.27 |
| 8 | 51.18 | 52.34 | 1.16 |
| 9 | 61.99 | 61.61 | -0.38 |
| 10 | 44.13 | 46.00 | 1.86 |
| 11 | 50.94 | 52.18 | 1.23 |
| 12 | 62.97 | 64.52 | 1.55 |
| 13 | 58.07 | 60.43 | 2.36 |
| 14 | 57.39 | 57.57 | 0.18 |
| 15 | 58.00 | 60.56 | 2.55 |
| 16 | 55.43 | 58.45 | 3.02 |
| 17 | 57.31 | 59.52 | 2.21 |
| 18 | 55.74 | 57.53 | 1.79 |
| 19 | 59.66 | 61.51 | 1.84 |
| 20 | 54.64 | 56.39 | 1.74 |
And if we run a paired samples t-test, we get the following results. This result is very close to the original data in Navarro & Foxcroft (2019, sec. 11.5, figure 11.16).
PAIRED SAMPLES T-TEST
Paired Samples T-Test
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
statistic df p Effect Size
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
grade_test2 grade_test1 Student's t 8.191378 19.00000 0.0000001 Cohen's d 1.831648
───────────────────────────────────────────────────────────────────────────────────────────────────────────────
Note. Hₐ μ <sub>Measure 1 - Measure 2</sub> ≠ 0
Descriptives
─────────────────────────────────────────────────────────────────────
N Mean Median SD SE
─────────────────────────────────────────────────────────────────────
grade_test2 20 57.59122 57.84745 6.738242 1.506717
grade_test1 20 55.80603 55.91381 6.638070 1.484318
───────────────────────────────────────────────────────────────────── 6.2.2.4 Reporting the output
See section 12.4.1.3.2 for a review of how to report the specific t-test statistics in APA format.
One could report the null findings from the first pair of randomly generated variables in the following way:
Students scored higher on average during the second exam (M = 57.1, SD = 5.19, N = 20) than during the first exam (M = 55.8, SD = 6.64, N = 20). However, the difference in means was quite small, and there was no statistically significant effect of time of test, t(19) = 0.664, p = 0.514. The effect size was also quite small, d = 0.149. Students are doing no better or worse on average during the second exam, compared to the first.
But the second randomly generated (but correlated) data set would be significant, and reported as follows:
“Students scored higher on average during the second exam (M = 57.6, SD = 6.74, N = 20) than during the first exam (M = 55.8, SD = 6.64, N = 20). Although the difference in means was quite small, there was a statistically significant effect of time of test, t(19) = 8.19, p < 001. The effect size was also quite large, d = 1.83. Students are doing better on average during the second exam, compared to the first.”
6.2.3 Advanced 2: Singing parents
This is another real data set from a real study. The description of the study is below, followed by the relevant tasks you need to carry out, as well as some useful information to get you started.
6.2.3.1 Study description
The following activity is another partially altered version of one developed by McIntyre (2016).
Parents often sing to their children and, even as infants, children listen to and look at their parents while they are singing. The research here by a couple of Harvard researchers sought to explore the psychological function that music has for parents and infants, by examining the hypothesis that particular melodies convey important social information to infants. Specifically, melodies convey information about social affiliation.
The authors argue that melodies are shared within social groups. Whereas children growing up in one culture may be exposed to certain songs as infants (e.g., “Rock-a-bye Baby”), children growing up in other cultures (or even other groups within a culture) may be exposed to different songs. Thus, when a novel person (someone who the infant has never seen before) sings a familiar song, it may signal to the infant that this new person is a member of their social group.
To test this hypothesis, the researchers recruited 32 infants and their parents to complete an experiment. During their first visit to the lab, the parents were taught a new lullaby (one that neither they nor their infants had heard before). The experimenters asked the parents to sing the new lullaby to their child every day for the next 1-2 weeks.
Following this 1-2 week exposure period, the parents and their infant returned to the lab to complete the experimental portion of the study. Infants were first shown a screen with side-by-side videos of two unfamiliar people, each of whom were silently smiling and looking at the infant. The researchers recorded the looking behavior (or gaze) of the infants during this ‘baseline’ phase. Next, one by one, the two unfamiliar people on the screen sang either the lullaby that the parents learned or a different lullaby (that had the same lyrics and rhythm, but a different melody). Finally, the infants saw the same silent video used at baseline, and the researchers again recorded the looking behavior of the infants during this ‘test’ phase. For more details on the experiment’s methods, please refer to Mehr et al. (2016) Experiment 1.
6.2.3.2 Getting the data
This open data set is located on Canvas at Lab: Lab manual data sets > TwoMeans_InfantMusic.csv (or as an .omv file). Again, the missing value for this .csv file is a blank. So set the Default missings to two side-by-side quotation marks: “”
6.2.3.3 Adjusting the data
The first thing you will need to do is filter the experiments down to only those for Experiment 1.
The data are deliberately set up such that you can use a filter to restrict the data. There are three variables in the data set named, respectively, exp1, exp2, and exp3. You only need the first for this. It is coded “1” if that observation (row) corresponds to Experiment 1, and “0” if it corresponds to Experiments 2 or 3.
You do this by going to the Data tab in jamovi, and finding the Filters icon. Click it and a window will pop up. The filter will be named Filter 1, and a new column will appear on the left of the spreadsheet. The filter formula goes into the box to the left of the formula symbol \((f_{x})\). In this box, you should type in the following: exp1==1.
The results of this process should look similar to Figure 6.11 below.
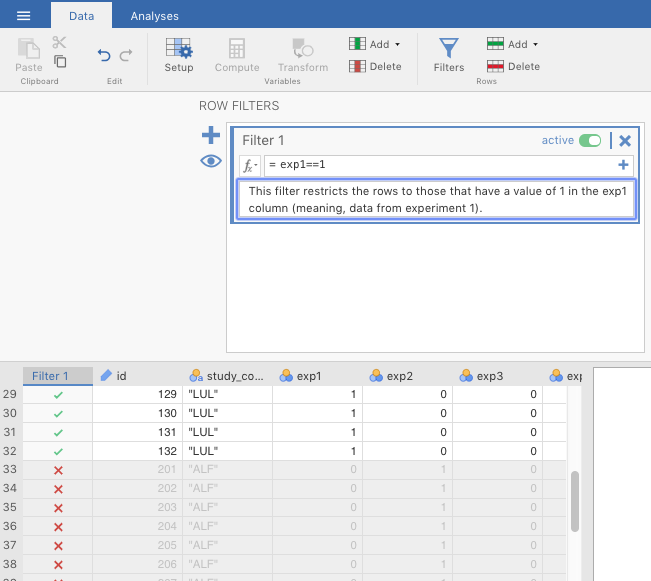
Figure 6.11: Creating a filter in jamovi.
6.2.4 Your tasks
- Explore the data file. Note, you will not analyze all of these variables. Try to find the variables that are relevant to the study description above (Section 6.2.3.1.
- Next, you want to demonstrate that infants attended equally to the two singers during the familiarization trials. Run a paired samples t-test comparing the
Gaze to Familiar Songvs. theGaze to Unfamiliar Song.
- Finally, compare looking behavior at baseline to looking behavior at test, using a paired-samples t-test.
- Prepare an APA-style results section to describe each of the analyses conducted above.
6.3 Outside help on t-tests
datalab.cc has a nice introduction to the purpose of these tests (minus the one-sample z-test). Choose video #26 (t-tests: chapter overview). You can also find this at Texas A&M via the Howdy! portal as tutorials in LinkedIn Learning.
6.3.1 Independent samples t-test
For a just-the-basics online tutorial on the independent samples t-test, go to the jamovi quickstart guide.
datalab.cc’s tutorial has a more extensive video tutorial. Choose videos #27.
You will also find online tutorials at Statistics for Psychologists (Wendorf, 2018). Choose JAMOVI > JAMOVI: Using the Software. Scroll to the table of contents, and click INDEPENDENT SAMPLES T TEST. On the same website, you can find a tutorial for interpreting the output. Just go to JAMOVI > JAMOVI: Annotated Output. Then scroll down to the table of contents and choose T-TEST (INDEPENDENT SAMPLES). The annotations are based on a slightly older version of jamovi, but they will suffice.
Your main textbook (Navarro & Foxcroft, 2019) covers this in Sections 11.3 and 11.4.
6.3.2 Paired samples t-test
For a quick online tutorial on the paired samples t-test, go to the jamovi quickstart guide.
datalab.cc covers paired-samples t-tests in video #28.
You will also find online tutorials at Statistics for Psychologists (Wendorf, 2018). Choose JAMOVI > JAMOVI: Using the Software. Scroll to the table of contents, and click PAIRED SAMPLES T TEST.You can also find there a tutorial for interpreting the output. Just go to JAMOVI > JAMOVI: Annotated Output. Then scroll down to the table of contents and choose T-TEST (PAIRED SAMPLES).
Your main textbook (Navarro & Foxcroft, 2019) covers this in Section 11.5.
References
In some cases, you can use a paired-samples t-test for different groups of people, but they must be highly matched (e.g., identical twins, kids from the same home).↩︎
Student’s t would have been called Gossett’s t, had it not been for the strange policies of Gossett’s employer, Guinness Brewing in Ireland. For more on this, see Navarro & Foxcroft (2019), Section 11.2.1., or here↩︎
Actually, its programmers are smart.↩︎
Recall that the output below (and further down) was generated from the jmv package in R, and will therefore be rounded to more decimal places than the native output in jamovi.↩︎
The use of the term marginally significant is a bit controversial. It means that the p-value was close to going below .05, but didn’t quite get there.↩︎
using something called factor analysis, which is covered in Navarro & Foxcroft (2019) Chapter 15, but which we don’t cover in this class↩︎
a better choice in our opinion as well as that of Navarro & Foxcroft (2019); see Sections 11.3.7 and 11.4; also see Delacre et al. (2017), linked here↩︎
the lines above and below the circle; see Navarro & Foxcroft (2019) Chapter 8 (specifically Section 8.5) for a discussion of confidence intervals↩︎
We could have split up counts of the new variable in a different way e.g., 1-2 in one group and 3-5 in another, but this is definitely the most efficient since the vast majority of respondents answered 1 (Totally disagree)↩︎
Note that if were were serious researchers trying to get this published in a peer-reviewed journal, we would probably get some resistance from a reviewer since our transformation was so extreme. They might ask us to re-collect our data using yes/no scale directly, instead of relying on a transformation. This is not unreasonable. After all, what we did was we made several assumptions about how participants would have responded if the scale had been pitched differently. But we don’t know that they would have responded that way; we can only assume so, which may not be enough for science.↩︎
This is also true of the big sister to the paired samples t-test: the repeated measures ANOVA, which we won’t get in to here, but can be found in the main textbook (Navarro & Foxcroft, 2019), section 13.8↩︎
The more modern way to do this kind of analysis works more like the independent samples t-test with a Split by variable, but this approach, called multilevel modeling or mixed-effects modeling is well beyond the scope of this class. However, for what it’s worth, it is mentioned in your main textbook (Navarro & Foxcroft, 2019), in section 17.1.2, under the bullet point labeled Mixed Models (apologies or the multiple names for identical concepts; it’s one of the curses of statistics).↩︎
You could do this in either order, but we are following Navarro & Foxcroft (2019, sec. 11.5.3). Presumably, they did this in order to get a positive value for Cohen’s d, in order to reduce confusion for the reader.↩︎
This is actually a very useful procedure in the world of data analysis, but it only serves as an illustration here.↩︎