Chapter 2 Basic data operations
This chapter helps you through a number of issues that have to do with data entry, opening it, exploring it, importing it. exporting it, modifying it, etc. The best way to learn in this chapter is to follow along in each section using jamovi on your own computer.^{\(\dagger\)} There are also some extra practice exercises at the end of the chapter.
\(\dagger\) Note that the most recent versions of jamovi (2.0 and later) have added a Variables tab. This is a very useful tool, but it was introduced in mid-July, 2021. There has not been enough time to update this manual accordingly. However, if you choose to use it, just understand that this lab manual and the the version of jamovi your using may differ a little bit. That said, the Variables tab almost certainly makes things easier.
2.1 Entering data manually
Okay, about the only people who enter data manually anymore are students who are learning about statistical analysis software.12 Nonetheless, entering data manually is a great exercise in getting to know any statistical-analysis software, like jamovi. In fact, there is one case where entering data manually serves a unique purpose in jamovi. We’ll get to that at the end of this chapter since it is not critical.
When you start jamovi, or open a new document (i.e., \(\equiv\) > New), you will see three default variable names, A, B, and C, in the the three leftmost columns of the spreadsheet (jamovi expects you to change these variable names). There is also a tiny, grayed-out column on the far left that gives you the row number of the spreadsheet. The default scale of measurement for variables A, B, and C is nominal (categorical). To see this, just double-click A, B, or C. See Figure 2.1
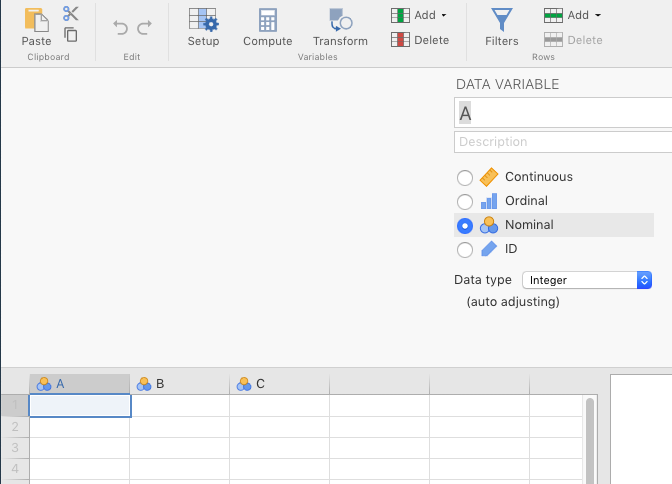
Figure 2.1: Default view of variables in jamovi.
As long as you’re doing this, you might as well save this file as YOUR.LASTNAME_YOUR.FIRSTNAME_jamoviPractice.omv,13 or something like that.
The point of saving the file this way is to emphasize a few things:
- jamovi is a desktop application (not a cloud-based program), so you actually do need to save files on your hard drive
- You should always use meaningful file names so that you can identify what’s in them later on
- You should have your name in the title of almost any document that you share with your instructor or TA (receiving 22 documents that are all titled
MyJamoviPractice.omvcan be pretty frustrating)
Back to the task at hand…
When you double-click on the variable name (or single-click, followed by Data > Setup), you’ll see the details of that variable. The topmost box will be the official variable name. This variable name should be short enough to keep you from having to type out really long names repeatedly (e.g., use Eighth Grade Aggression instead of the aggression measurements of kids in the eighth grade), but not so short that the meaning of the variable becomes opaque (e.g., use Eighth Grade Aggression instead of 8GA). 14
The next box down, Description, is an alternative description for the variable. This is basically for the researcher’s notes. Be as descriptive as you like. It won’t be output to any graphics or analyses.
Below that on the left, you’ll see a vertical series of four buttons. These define the scale of measurement that the variable represents. We only use nominal, continuous, and ID in this course. Implicit in continuous are two possible scales: interval and ratio. Using the drop-down box to the right of the button selections, interval data should technically be coded as integer. See Figure 2.2 for an example.
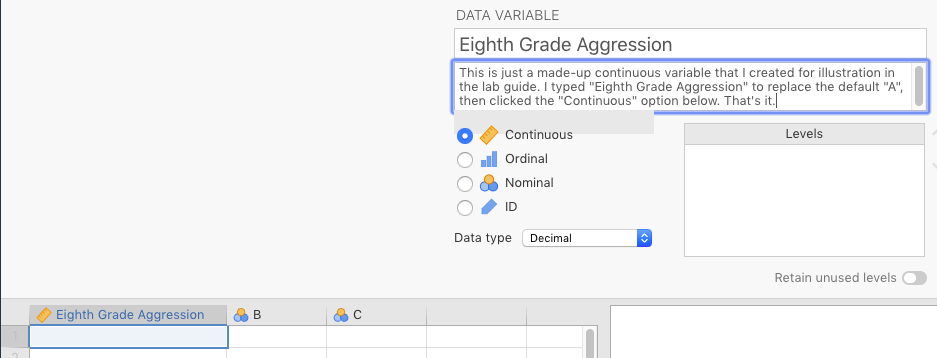
Figure 2.2: Re-labeling and changing the scale of measurement.
The ID variable is just an anonymous substitute for a participant’s name. It’s either a pseudonym (a fake name, like AAB or Los Angeles or frogma) or a number, but for analysis purposes, it’s just a unique label, not a number. The main requirement is that no unique ID can refer to more than one observation (e.g., person, rat, neuron, etc.).
If one or more of your variables is nominal, then you will need to define the levels, which appear in the box to the right, labeled Levels. But the levels won’t appear there magically, if you have a variable Gender with three levels (with 0 for female and 1 for male), then first you’ll need to type in the numbers you need in that column directly in the spreadsheet. These numbers will then appear automatically as the levels in the Setup window for that variable.
This is where you’ll need to double-click the box for 0, and type over it with female, and then do the same for 1, and replace it with male (don’t do this in the spreadsheet, but rather here, in the DATA VARIABLE menu above the spreadsheet). What you do here matters for several functions that you will carry out later, particularly graphics. So it’s a good idea to get this right, and to to be consistent for any nominal variable you have.
In Figure 2.3 below, we’ve created the variable Sex, made it Nominal/Integer and coded 0s as male and 1s as female.15
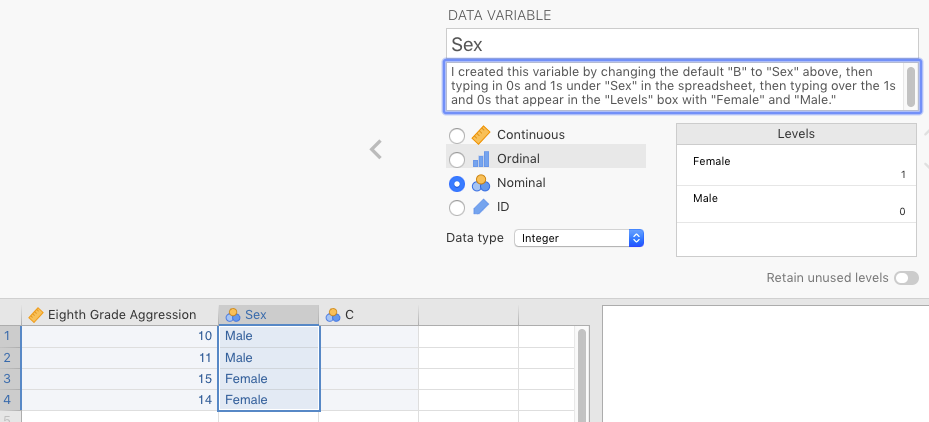
Figure 2.3: Assigning values to factors.
Now that that’s done, if you start entering the real data manually in the spreadsheet, one of three things will happen.
- If your data is continuous, and you enter a number, it will stay as that number. Note however, that the maximum number of decimal places that jamovi will display (irrespective of how many you enter) is defined under preferences, or (\(\vdots\)) >
Results>Number format.
- If your data is nominal, with numbers representing levels (e.g.,
0=female), then as you enter a number in the spreadsheet (say1, underSex), that cell will turn intomaleas soon as you enter a1in there. Underlyingly, it is a1, but jamovi is displaying it asmaleto you.
- If you have your nominal variable coded as text, then you can just type in the level in here (e.g.,
female).
jamovi can deal with both (2) and (3) above for analysis, but method (3) is not really recommended as it’s much more likely that you’ll accidentally introduce a new, unwanted level through misspelling (e.g., famale). See Figure 2.4 below for an example of this, which you might not notice browsing through the spreadsheet.
That said, when using method (2), it’s a good idea to make sure that in the drop-down menu under Data type you choose text. Otherwise, you will get some confusing (albeit harmless) statistics when carry out Descriptives (the topic of Chapter 3).
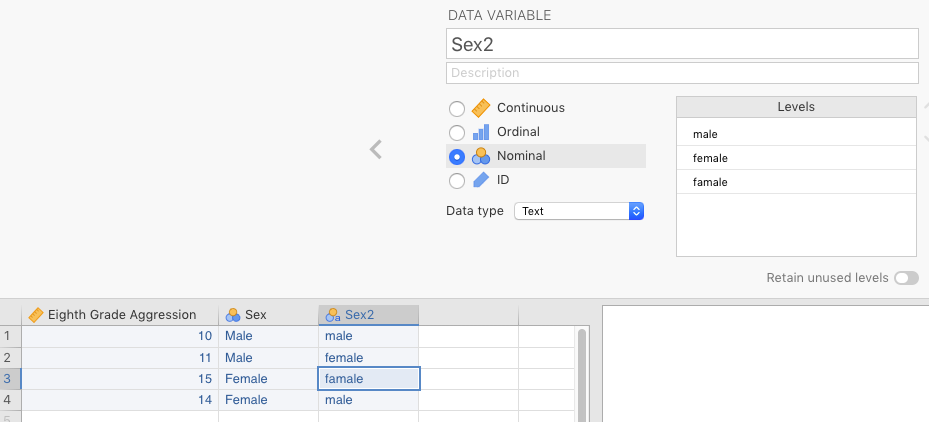
Figure 2.4: Relative difficulty in seeing a bad level when the data is entered as text.
In contrast, if you make a mistake and enter a 2 instead of a 0 or a 1 for Sex, you’ll see a 2 there. It will stand out like a sore thumb. See Figure 2.5 for an example of this.
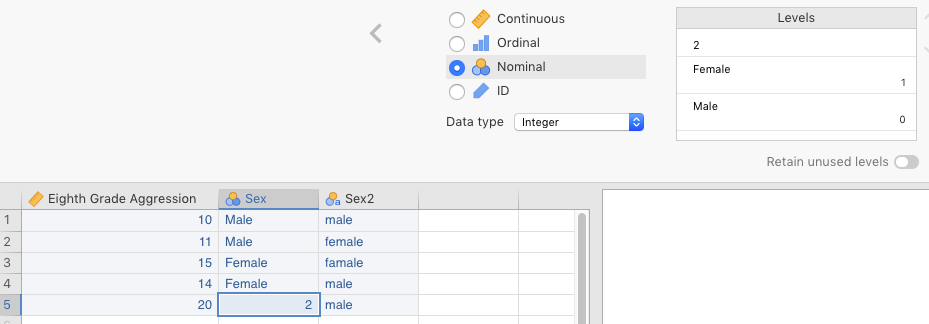
Figure 2.5: Relative ease in seeing a bad level when the data is entered as a number.
You can find a practice exercise for this section below: Practice Exercise 2.8.1.
Now on to something much simpler, but also much more reflective of what you will actually be doing with data: Opening existing data files.
2.2 Opening data files
This really isn’t so much about how to open files (something we assume you all learned back in elementary school), as it is about what files are available to open in jamovi in order to get used to how data looks and works in the software.
jamovi comes with a few sample data sets pre-installed. They can be found by clicking (\(\equiv\)) > Open and choose one of the four default sample data sets.
If you haven’t already done so, you should also install the module for the main textbook for the class (Navarro & Foxcroft, 2019). To install it go to Analyses > Modules (+) > jamovi library > Available > learning statistics with jamovi > Install. As noted above, you’ll find the sample data sets (all from Psychology) under (\(\equiv\)) > Open > lsj-data. The main textbook will refer to these data sets throughout the course. You can see this step in Figure 2.6 below. Also, in contrast to the four default data sets in jamovi, not all the data sets from Navarro & Foxcroft (2019) are native-jamovi .omv files; some of them have different file extensions, like .csv. We’ll get to that, especially under 2.3. Finally, as noted in Section 1.3.2 in the last chapter, you should also install the module called R data sets, as you will work with one or more of these in this lab manual.
Figure 2.6: Finding sample spreadsheet data in jamovi.
2.3 Importing data
jamovi is not data-collection software.16 This means that when the data file is not given to you from within jamovi (e.g., sample data sets), you will need to obtain the data from wherever you collected it into jamovi. This is known as importing data.
There are a variety of ways that this might take place, but two of them are far more common than others:
- importing data from a proprietary data format
- importing data from a non-proprietary delimited text file
A proprietary data format is primarily one generated by commercial software. For instance, SPSS stores its data in .sav files. SAS stores its data in .*SAS*7bdat files17 and Stata in .dta files. Usually, jamovi will open these directly as it uses powerful R packages, like haven, that know how to open these files. Just click (\(\equiv\)) > Open > This PC > Browse and find the file that you need to open (it needs to be downloaded on your computer already).
But the most convenient and reliable way to transfer data from computer to computer and software to software is through an intermediate data-file structure known as a delimited text file. This is a plain-text file that can be opened by pretty much any software (free or commercial) that reads text files in any way. A plain-text file is really the simplest of file formats. But a delimited text file is a special case: It takes data that is in table format, and converts it into plain text, where rows from your data frame usually correspond to new lines, and column boundaries from within rows in the data frame are converted into specific characters, like commas, semicolons, or tabs. The top-most row often, but not always, contains the variable names (the header). An example of such a file can be seen in the jamovi Quickstart Guide.
We converted the data set from Navarro & Foxcroft (2019) called Clinical Trial into both comma-delimited and tab-delimited files. When you open them up with a simple text editor like Notepad or Text Edit, you’ll see something like Figure 2.7 below. It is in raw, plain-text, comma-separated (.csv) format on the left, and in its tab-delimited format (.txt or .tsv) on the right.18


Figure 2.7: Examples of comma-delimited (left) and tab-delimited (right) files
jamovi opens delimited text files just as easily as proprietary data files. In Excel, there’s generally a wizard that you have to get through to import delimited files. In contrast, jamovi imports them directly with no wizard. One downside to this faster process is that you encounter mistakes once in a while. This is because jamovi is “guessing” the appropriate file format. These mistakes are easy to correct in most cases.
Just click (\(\equiv\)) > Open > This PC > Browse and find the delimited file. jamovi will do its best to import the data. It pretty much always works unless there is something wrong with the data file itself. You can try this yourself by opening the data set booksales, located at the top of the data sets available from Navarro & Foxcroft (2019). Just go to (\(\equiv\)) > Open > Data library, and look for booksales at the top. It’s a comma-delimited text file. It opens up quite easily. However, you will need to go in and change the data types for a few variables. It seems to treat numbers as nominal data.
Beware however, that jamovi will sometimes import defective delimited files and assume that they’re not defective. This results in a bad data set. You often need to check your visually. If you data set is large, then you can use descriptive statistics (covered in Chapter @ref(Descriptive Stats)) to find evidence of this kind of problem. To illustrate this, we deliberately distorted a file containing reaction times, and then imported it through jamovi. In this case, we removed the commas from the very last line of data. The results can be seen below in Figure 2.8 below.
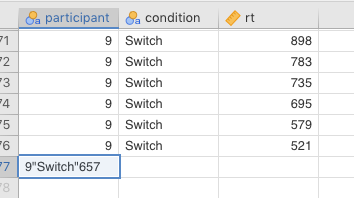
Figure 2.8: jamovi importing a bad comma-delimited file, where the final line of data had its commas removed.
As you can see, there were supposed to be 3 columns of data: an ID variable (participant), a condition variable, and the dependent (outcome) variable rt (for reaction time). But since the commas were removed from the last line, jamovi thought that all three variables were really just one, and assigned that value to participant. You should always be on the lookout for such data-import errors in your own work.
For practice on importing data, go to Practice Exercise 2.8.3, but you might want to wait until you read the next section, as well as do the practice exercise for exporting. The reason is that you will be importing data that you export (from Google Sheets, or manually) for those exercises.
2.4 Exporting data
All statistical software (e.g., SPSS, SAS), all spreadsheet programs (e.g., Excel, Google Sheets), and all database software (e.g., MS Access, SQL, Filemaker) will export their native tables/data frames into delimited text file formats. Crucially for those of you collecting your own data in groups, Google Forms also does this (as long as you have already collected some data). You should take advantage of exporting your data into delimited text files in all cases except when you are absolutely positive that your colleague has the exact same software as you do (e.g., you both have jamovi, or SPSS, or SAS, etc.).
The comma-delimited file usually has a specific .csv extension (meaning “comma-separated values”). Tab-delimited files use a .tsv or just .txt extension.
NOTE: There is something you should understand about these delimited text files however. This is ultimately not that important, but may help to eliminate some confusion down the road. Delimited text files are non-proprietary (not owned by any particular company). So like we said, just about any software can open them and read them as they are supposed to be read.
Moreover, the file extensions that go with them (e.g., .csv, .tsv) are simply informal user conventions that serve as “clues” for your computer and/or software as to how to open them. So a .csv extension tells your software that it is likely (but not assured) that this is a delimited file with commas acting as delimiters. The less-universal .tsv extension tells your software to guess similarly, but to expect tabs instead.
All this helps explain a common phenomenon that many novice data analysts find confusing. Specifically, many data-collection software programs say that they will export to Microsoft Excel, and do so with an .xls file extension. Then when you open it with Excel (which your computer will probably do automatically if Excel is installed), Excel tells you that it is not actually an Excel file after all, and that you have to import it as a delimited-text file.
This is confusing until you realize that what these software programs are doing is creating a valid, text-delimited file, but arbitrarily pasting an .xls extension to the end of of the file name. The extension tells your computer to use Excel specifically to open it (and Excel can do so), but since it is not actually a proprietary Excel file, Excel will instead sent it through a delimited-file import procedures (a “Wizard”).
You can actually try this trick yourself by clicking any delimited text file that you have created, and changing the extension to .xls. Then double-click it. If you have Excel installed, your computer will probably call up Excel to open it, but then Excel will have to import it.
One thing you want to ensure is that you don’t have any of these special delimiters inside the values of your delimited file. This will split up your data in places you don’t want it to split. For this reason, linguists, for instance, often avoid comma-delimited files since a lot of language data has commas in it (e.g., passages scraped from the Web). Linguists would prefer something like tabs, or something never used in natural text, like pipes.19
You also have to be careful receiving data from countries that use commas to indicate decimals instead of periods. Finally, you can also create your own delimiters (e.g., the pipe, or semicolons), but you will need to inform your colleagues what your non-standard delimiter is before you share the file with them. Data-analysis software programs always have options do deal with these sorts of exceptions
For practice on this, go to Practice Exercise 2.8.2. And don’t forget to follow that exercise with the practice exercise on importing data (Practice Exercise 2.8.3).
2.5 Manipulating data
The three main types of data manipulation that you can carry out in jamovi are transforming, computing, and filtering. We will only cover the latter two here. Data transforming in jamovi is for creating formulas that can be applied to multiple variables. It is a bit beyond the scope of this course, but a nice tutorial from datalab.cc can be found here as the video labeled Transforming scores to categories.
2.5.1 Computing new variables
We are going to show you three different ways to compute new variables in this section:
- Re-coding new variables based on the values in existing variables
- Generating random variables
- Creating data transformations
2.5.1.1 Re-coding new variables
You can add a new variable to a data set, based on variables that you already have. One of the most common reasons to do this is if you have one or more other variables already in your data set that you want to derive alternative information from in order to change your analysis or make it simpler.20 For instance, you may have a variable called ClassLevel that has the following four levels: Freshman, Sophomore, Junior, and Senior. But it is possible that you’d want to create a new variable called ClassLevelStatus (for lack of a better term), with the following two levels: Upperclassman and Underclassman.21
Doing something like this is pretty simple. As illustrated in Section 2.1, you can create an artificial data set with, say, four observations each of Freshman through Senior under a variable called ClassLevel. But now we want to create a new variable called ClassLevelStatus.
We started by going to the Data tab in jamovi, double-clicking the header of a blank variable, and clicking the \(f_{x}\) NEW COMPUTED VARIABLE icon in the middle of the list. We gave the new variable the name ClassLevelStatus (the default was a letter, like D).
You should now have something that looks similar to Figure 2.9 below.
Figure 2.9: Initial window when computing a new variable based on an old variable
To create the new variable, we needed a nested if-then-else formula.22 We could have clicked the \(f_{x}\) drop-down box and found the IF() function under the Logical: heading. But we needed something more complex. The syntax for what we needed is below. We just typed this in to the box next to \(f_{x}\).
IF(ClassLevel=='Freshman','Underclassman',IF(ClassLevel=='Sophomore','Underclassman',IF(ClassLevel=='Junior','Upperclassman',IF(ClassLevel=='Senior','Upperclassman','error'))))
You can interpret this formula in plain English as follows:
- IF the value of
ClassLevelisFreshman,- Then place the value
Underclassmanhere, under the current variable (ClassLevelStatus).- (Else) IF that’s not the case, then check to see if the level is
Sophomore;- If it is, then also put
Underclassmanhere.- (Else) IF that’s not the case, then check to see if the level is
Junior;- If it is, then put
Upperclassmanhere.- (Else) IF that’s not the case, then check to see if the level is
Senior;- If it is, then put
Upperclassmanhere.
- If it is, then put
- (Else) IF that’s not the case, then check to see if the level is
- If it is, then put
- (Else) IF that’s not the case, then check to see if the level is
- If it is, then also put
- (Else) IF that’s not the case, then check to see if the level is
- Then place the value
- ELSE (which means none of those other conditions were true) put
errorhere.23
After we did this, jamovi looked like the Figure 2.10 below.
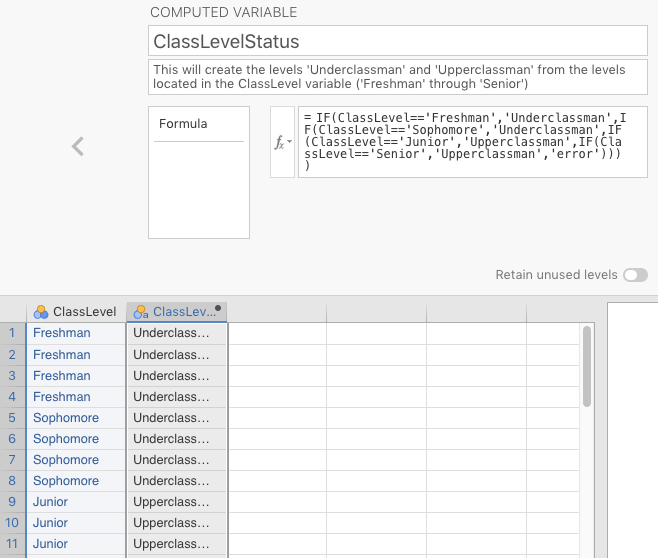
Figure 2.10: Computed-variable window after the nested if-then-else formula was added.
Note the new values that populated the ClassLevelStatus variable in the spreadsheet.
What’s going on is that the basic formula is if-then-else, but the else part of the formula is replaced with another if statement.24 This is nesting, and it is very, very useful for re-coding variables.
NOTE: You might be wondering why we need two equals signs (==) in the computed variable, and not just a single equals sign (=). Recall that jamovi is based on R. In R, two equals signs are used for evaluating particular values. In this case, it can be interpreted as “where it is equal to.” In contrast, a single equals sign (=) is used for various other, common operations, including the creation of variables, the assignment of arguments to functions, etc.
In addition, the exclamation mark (!) means NOT in R and jamovi. So != means “where it is not equal to.” Thus, the equivalent for our purposes would be =ClassLevel != 'Freshman' (i.e., “if the value is NOT ‘freshman’, then…”).
For numerical variables you can also use the symbols < for “less than”, > for “greater than”, <= for “less than or equal to”, etc.
Your main textbook (Navarro & Foxcroft, 2019) covers this in Section 6.2.
You might also have noticed the weird sequence of closing parentheses at the end of the formula. This is due to the fact that each IF() statement must have both opening and closing parentheses. The open throughout the formula, but only close at the end. They are actually embedded, like If(IF(IF(IF))), similar to russian Matryoshka dolls.
2.5.1.2 Generating random data
As noted above, there is a special case of manual data entry that you might find yourself doing for this lab. Many software programs can generate data randomly [e.g., the RAND() and RANDBETWEEN() functions in Excel]. In jamovi, this can be done quite easily.
Go to the Data tab. Then create a new variable by double-clicking at the top of a blank column. You will see a small menu appear with NEW DATA VARIABLE, NEW COMPUTED VARIABLE, and NEW TRANSFORMED VARIABLE. See Figure 2.11, below, for a depiction of what you should see.
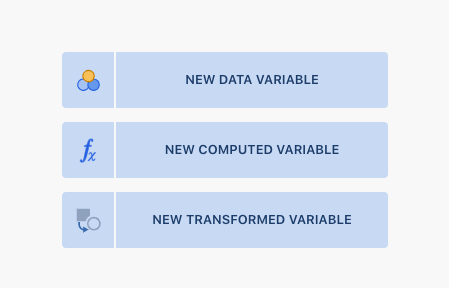
Figure 2.11: Options for creating new variables.
Click the middle one: NEW COMPUTED VARIABLE. Give the new variable an appropriate name. The example we have chosen Random Normal, which means that it’s going to result in numbers generated randomly from a normal distribution that we define with a mean and standard deviation that we specify (our choice). There is a small box labeled \((f~x~)\). Click it and scroll down to the bottom of the Functions window where it finally says Simulation. See Figure 2.12, below, for a depiction of what you should see.
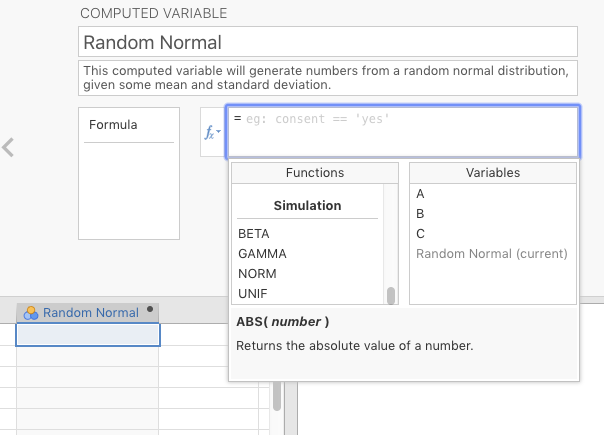
Figure 2.12: Finding the formula for a random normal distribution
Double-click NORM, and then look in the box to the right of \(f_{x}\), and you’ll see the following formula: =NORM(). Between the parentheses, type in two numbers separated by a comma. The number to the left of the comma will be the mean of your randomly generated data, and the number to the right of the comma will the standard deviation of that data. For illustration purposes (see below), we have chosen the mean to be 65, and the standard deviation to be 16. You can choose whatever values you want. Press the ENTER/RETURN key.
Once you do that, start typing in numbers (or names, or whatever) in one of the other default columns (you can rename it ID later, if you were so interested). You can also skip rows (as we did to illustrate). Then look what happens under the variable Random Normal. You should see random numbers being put into the cells between the topmost row with a value, and the bottom-most row with a value. These are randomly generated by jamovi. The results of this little simulation here can be seen below in Figure 2.13 below.
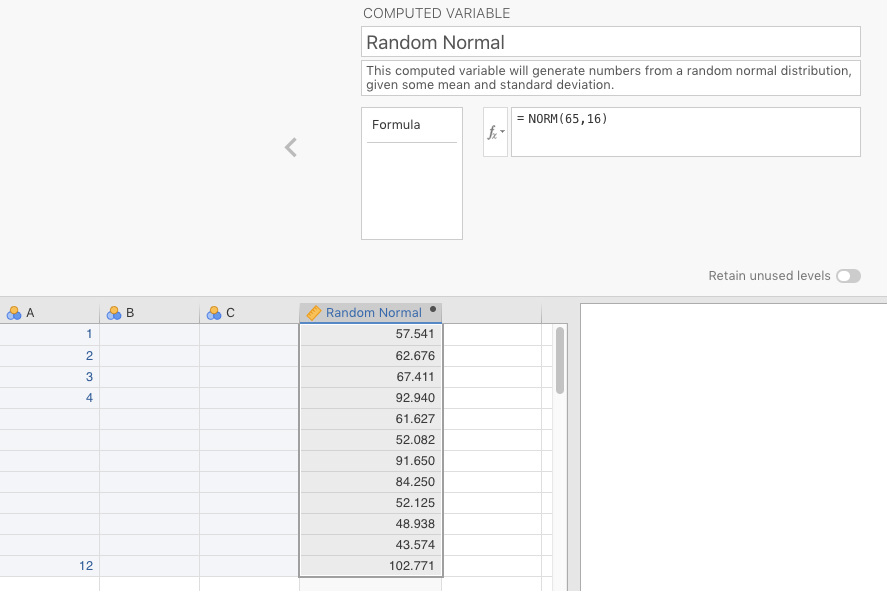
Figure 2.13: Inserting the formula and observations for a random, normal distribution with a mean of 65, and a standard deviation of 16.
You will get some actual practice doing this in a later exercise (Section 6.2.2).
2.5.1.3 Data transformations
Sometimes variables have inherently non-normal distributions. This makes them difficult (though not impossible) to analyze because there’s an important assumption that applies across all the types of statistics that we do in this class (with the notable exception of chi-square (\(\chi^2\)) in Chapter 5). This assumption is that the residuals (or deviations) are normally distributed. These are the distances of each observed value from the model (in the case, the model is the mean).25 If you measure all these distances, and put them in, say, a histogram, you should see a normal distribution (i.e., a bell curve). If you don’t see a bell curve, then you often have to take further measures, like apply a transformation.
For instance, reaction-time data is almost always skewed positively. The reason for this is that although you can take almost as long as you want to press a button in response to a stimulus, it is very difficult for you to legitimately respond faster than, say, 300 milliseconds, even in the easiest of tasks. This means that really fast responders will have many reaction times near the low end, clustering around 300 ms, but a few at the high end (for a confusing stimulus, or perhaps they got distracted. There are many possible reasons, actually).
A solution that is typically applied in reaction-time analyses is the log transformation.26.
2.5.1.3.1 Log transformations
If you’ve forgotten what logarithms are, they are (in base 10) the value you need to exponentiate 10 by in order to reach the number in question. Thus, the logarithm of 1000 is 3 since \(10^3=1,000\). The log of 100 is 2 \((10^2=100)\), and the log of 10,000 is 4 \((10^4=10,000)\). You may have noticed that by doing this, the extreme values get disproportionately “pulled in” to the left. So a reaction time of 532 milliseconds (ms) is 2.726 \((10^{2.726}=532)\), and a reaction time of 2,345 ms is 3.37 \((10^{3.37}=2,345)\). So 2.726 and 3.37 are much closer to each other than 532 and 2,345.
Below is some raw reaction-time data.27 Our only purpose here is to show you the positive skew in a histogram, and how applying a logarithm to the data brings in the skew.
DESCRIPTIVES
Descriptives
──────────────────────────────────
rt
──────────────────────────────────
Standard deviation 555.0301
────────────────────────────────── 
Clearly, the reaction-time data is extremely skewed.
Now we will apply a log transformation to the data.
You can find this simulated, positively skewed, reaction-time dataset here: https://github.com/patrickabolger/ElemStatsLabManual/blob/master/datasets. Then right-click the file BasicDataPrep_RTdata.csv to download it.
When the data is opened, we changed theMeasure type of participant to ID. The variable to the right of that was the raw reaction times (rt). We double-clicked the column to the right of that, and then clicked the icon above labeled \(f_{x}\) NEW COMPUTED VARIABLE (not TRANSFORMED, ironically).
It automatically gets a letter name (e.g., C), but we changed that to log10_rt (for rt with a base-10 log transformation).
Just to the right \(f_{x}\) symbol, you can see a small down triangle \((\blacktriangledown)\). We clicked that and searched down for LOG1028 and double-clicked it. The formula for the transformation appears in the box to the right. Inside the parentheses we typed rt (since that was the variable we were applying the log transformation to). We then pressed enter, and watched as the new, logged values appeared in the new column.
Most of what we have described above appears in Figure 2.14 below.
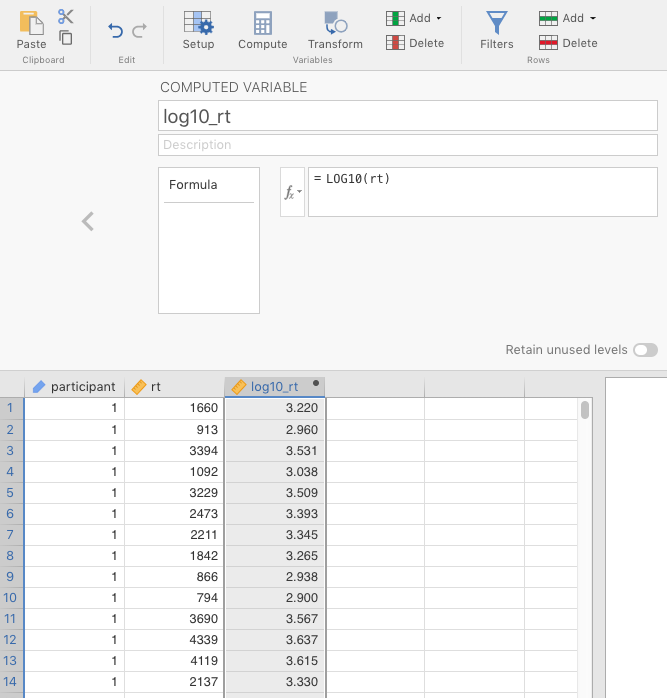
Figure 2.14: Parameter settings to apply a log transformation (base 10) to positively skewed data.
Now, we can create of histogram of the new, logged reaction-time variable. It is still slightly skewed to the right, but it is much better than before.29
DESCRIPTIVES
Descriptives
───────────────────────────────────
log10_rt
───────────────────────────────────
Standard deviation 0.1906327
─────────────────────────────────── 
2.5.1.3.2 z-scores
That said, it is probably warranted to remove a few outliers. The main textbook Navarro & Foxcroft (2019) covers outliers in Chapter 5, and in Chapter 12, but they deserve some more attention here. Using the same procedure as above, we will generate z-scores for the data.
What are z-scores?
Z-scores are used to re-cast raw scores of any interval or continuous variable into standard-deviation units. One advantage of this is that you standardize the scores. We’re not being tautological here.30 Rather, think of how standardized parts revolutionized manufacturing. Instead of each, say, wheelwright making wheels to their own dimensions, societies could invent standards that all manufacturers must follow. This made the world much easier to live in because you could get a wheel in one town, move to a different county or country, and replace the wheel there. You couldn’t do that before.
Standardizes scores (z-scores) are kind of the same thing. Whereas before you could not compare, say, raw IQ scores to raw cumulative school grades, standardizes scores let you do just that, as all continuous or interval scores can be converted into a scale where 0 describes the mean, whole integers refer to the number of standard deviations, and the polarity refer to whether that particular is above (+) or below (-) the mean. For example, a z-score of 0 means the average (the mean, \(\bar{x}\)); a z-score of 1 means “located at one standard deviation above the mean;” and a z-score of -1.75 means “located at 1.75 standard deviations below the mean.”
In jamovi, we calculate z-scores by clicking on a new, blank column, selecting \(f_{x}\) NEW COMPUTED VARIABLE, naming the new variable something like log_rt_zscores clicking the \(f_{x}\) box and scrolling down to the function Z, double-clicking it, followed by double-clicking log10_rt (under the right-hand column Variables) to place it in between the parentheses (or just typing the variable name there). This can be seen in Figure 2.15 below.
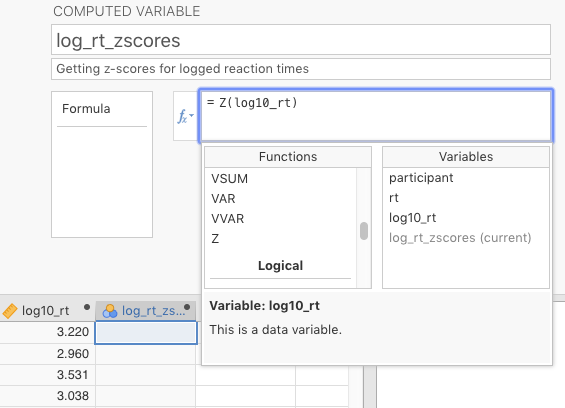
Figure 2.15: Parameter settings to calculate z-scores on the log transformation of the reaction-time data.
After pressing
Now let’s go back to the problem of extreme observations (i.e., outliers).
A conservative approach to filtering extreme observations is to remove observations with z-scores more extreme than 2 or 2.5 (positive or negative). These correspond to values that are beyond 2 or 2.5 standard deviations away from the mean, so they comprise about 5% or 1% of the observations, respectively.31 You can see why in the histogram below.

Below, we will show you how to remove these outliers, after we show you how to remove observations from participants who opted out of the study after their data had been collected.
2.5.2 Filtering data
Just like R, unless you tell jamovi otherwise, it will analyze all the observations (rows) in your data. All good statistical software does this.32 In order to restrict the analysis to certain rows, you need what is called a filter.
For instance, it is common to have a question at the end of a survey that asks the participant whether they are still comfortable with the researcher(s) using the data they provided for general analysis. The questions could be as simple as “Is it still okay to use your data for analysis? Remember, your data will be completely anonymized, and so in no way will it be traceable back to your identity.” Some people are not comfortable with having their data analyzed, and so they answer, “No.” Researchers are required to filter these observations out.
It is easy enough to create such a data set, so we will do so using the technique learned above in Section 2.5.1.2. We opened a new file in jamovi [(\(\equiv\)) > File > New]. Under column A, we typed in a 1 in the first cell, and changed the variable type to ID, and renamed the variable ID. For variable B, we renamed it Consent (with variable type set to Nominal and Text). Then we typed in Yes in the first cell. Finally, we deleted variable C, and double-clicked on a blank variable and chose NEW COMPUTED VARIABLE. We renamed that to rt, and then applied the NORM() function to the first cell (see Section 2.5.1.2 above). We arbitrarily set the mean to 615 ms, and the standard deviation to 112 [hence, NORM(615,112)].
We then typed in 20 in row 20 under ID. Under Consent we copied-and-pasted Yes from row 1 all the way down to row 18. But for the cells in rows 19 and 20, we typed No. This would mean that fake participants 19 and 20 did not consent to have their data used.
So then we needed to filter them out.
This was easy to do. The filter function is located under the Data tab. Once there, we just clicked the icon labeled Filters (at the upper-right). The icon looks like a funnel, half full of liquid. There’s a box there labeled ROW FILTERS. In the box under Filter 1, labeled \(f_{x}\), we typed in the following (the first “=” sign is provided by jamovi):
=Consent=='Yes'This filter equation could be read as follows, like a command to jamovi: “Create a new variable called Filter 1. For this variable, look under the variable Consent and return only the rows that have Yes as a value in the cell; filter out the others. You can see this below in Figure 2.16
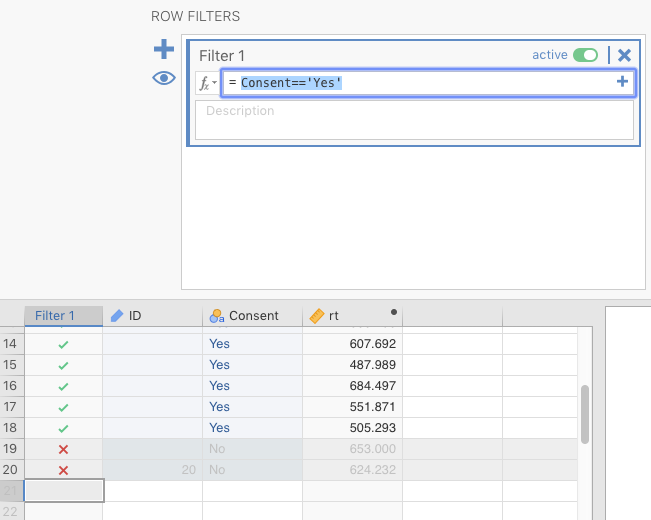
Figure 2.16: Results of applying filter (Consent==‘Yes’) to fabricated lack-of-consent data.
In the figure (or your own jamovi file, if you are following along), note the green check marks (\(\color{green}\checkmark\)) versus red times or (\(\color{red}\times\)) in the new filter variable that appears on the left under the new variable called Filter 1. This means that any subsequent analysis of our variables would be restricted to the observations with green check marks, and any with a red (\(\color{red}\times\)) will be excluded. That is, the analysis would only apply to people who had consented to have their data analyzed.[If you click the “eye” symbol, it will hide any row with a \(\color{red}\times\) in it. Click it back, however, before you proceed below, assuming you are following along.][Recall that the output below (and further down) was generated from the jmv package in R, and will therefore be rounded to more decimal places than the native output in jamovi.]
DESCRIPTIVES
Descriptives
──────────────────────────────────
rt
──────────────────────────────────
N 18
Missing 0
Mean 575.8419
Standard deviation 84.14402
────────────────────────────────── If you do a simple Descriptives procedure (see Section 3.2 in the next chapter), you can see that N = 18 (as above) since the procedure did not analyze the observations that were filtered out (i.e., #19 and #20).
To remove the logged reaction-time outliers described in Section 2.5.1.3 above, you would simple repeat the filter above, but the formula in the \(f_{x}\) box would be as follows (for deleting observations greater than 2.5 standard deviations from the mean). In this case, we are not using the z-score column we created; rather, we’re calculating the z-score within the filter formula.
-2.5 < Z(log10_rt) < 2.5This can be read as follows: “Filter in any values of log10_rt where the z-score of that variable is not only greater than -2.5, but also less than +2.5” (i.e., filter out the more extreme values that are either less than or equal to -2.5 or greater than or equal to +2.5). You can see this jamovi filter in Figure 2.17 below.
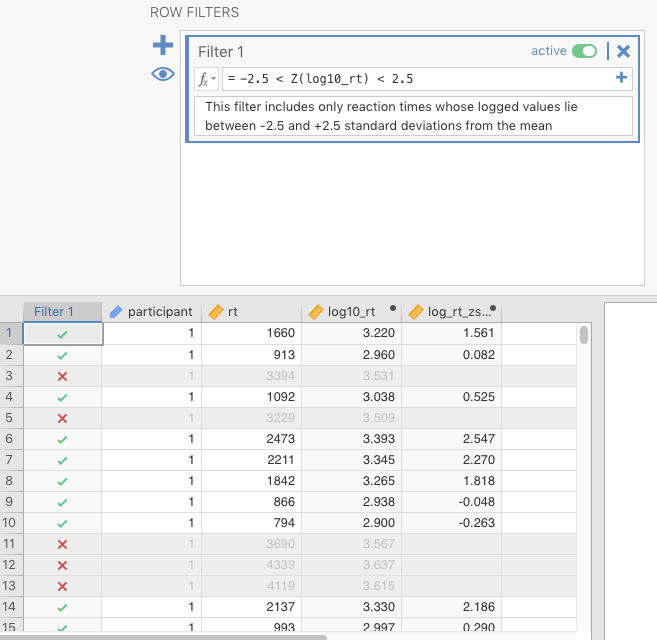
Figure 2.17: Results of applying filter to extreme (logged) reaction times.
2.6 General note: Understanding tidy-ness
This final section (before covering outside tutorials) is about understanding how data ought to be organized for easy analysis. As such, it’s less about how you prepare data in jamovi, and more about how you should structure data in general, irrespective of the software you are using.
Often, when working with data, researchers find themselves dealing with data that was entered in such a way that it can’t be analyzed statistically. This is usually data entered by people who are not used to doing statistical analyses.
You might fear that each statistical software program has its own way of organizing data for analysis, but we’re happy to tell you that your fears would be unjustified. As luck would have it (skill, not luck, actually), these programs are written by some very smart people, and they have converged on one and only one way of organizing data: Namely, tidy format.33. (Text-delimited files are covered in more detail in the next section) This universal data format has come to be known as tidy data format, a term we can probably trace back to Hadley Wickham, head programmer at RStudio (Wickham, 2014).
The briefest description is that in a tidy data set, all of the following are true:
- all columns are variables (outcome, predictor, or ID variables; but sometimes things like filters or even comments);
- all rows are observations (or cases): people, rats, etc.; and
- each cell below the header row is a single datum34 for that observation on that variable, with no data summaries.
Anything other than the tidy data structure above will usually cause problems with data analysis, something that is true across statistical-analysis software.
You will not have to worry too much about having non-tidy data sets in this class because, at least for your class projects, Google Forms automatically exports data in tidy format. The sample data sets from jamovi and the class textbook are all tidy.
But if you find yourself handling data as a professional some day, even if you are not doing statistics yourself, please remember tidy data format. This is especially true if you are preparing data for other data scientists (e.g., statisticians) to use. They will appreciate your efforts to make their lives easier.
2.7 Outside help on basic data preparation
datalab.cc has a general introduction to this part of data analysis. Go to video #9 (Wrangling Data) to see this. As noted previously, at Texas A&M, you can find it under the LinkedIn Learning tutorials through the Howdy! portal.
2.7.1 Entering and adjusting data
You should know that for a good overview of what is covered above, you can go to datalab.cc’s videos labeled Entering data and Variable types & labels.
2.7.2 Opening data
For further orientation as to how to do what we just explained above, watch the video from datalab.cc called Sample Data.
2.7.3 Importing data
At datalab.cc, go to the video labeled Importing data.
Your main textbook (Navarro & Foxcroft, 2019) also covers this in Sections 3.4 and 3.5.
2.7.4 Re-coding variables
There is no tutorial at datalab.cc, per se, for re-coding variables in the way described above in Section 2.5.1. However, it does have a nice tutorial on how to average two or more variables into a third. This is extremely useful sometimes. This video is labeled Computing means.
Your main textbook (Navarro & Foxcroft, 2019) covers this in a way not covered here. Specifically, it outlines how to convert a numeric variable to a discrete, nominal variable using formulas.35 This is Section 6.3.2 of the textbook.
There is also a tutorial on how to create a transform. Transforms in jamovi are saved functions that allow you to create new variables quickly according to the parameters of the function. This is usually most useful in large data sets with many variables. Go to datalab.cc and scroll the video labeled Transforming scores to categories. The jamovi blog (Love et al., 2019) also has a tutorial on this here.
Finally, your textbooks also covers this in Section 6.3.3.
2.7.5 Generating random data
There is nothing on datalab.cc. However, the jamovi blog has a short blog post on it (a mention, mostly) here.
2.7.6 Transforming variables
Go to datalab.cc and scroll to the video labeled Computing z-scores to learn how to transform your data into z-scores.
The jamovi blog also has a post on computed variables here
Finally, your main textbook (Navarro & Foxcroft, 2019) covers this in section 3.3.2. And it covers logarithms and exponentials in Section 6.4.
2.7.7 Filtering data
Go to datalab.cc and scroll down to video #16.
The jamovi blog (Love et al., 2019) also has an introduction to filters here.
Your main textbook (Navarro & Foxcroft, 2019) covers this in Section 6.5.
2.8 Practice Exercises
2.8.1 Practice entering data
Here is some practice, Exercise 2A, Manually Entering data.
2.8.1.1 The data
The textbook by Navarro & Foxcroft (2019) includes a data set about a clinical trial called Clinical Trial involving 18 participants divided into two therapies: Cognitive Behavioral Therapy (CBT) vs. no therapy (no.therapy). This variable is labeled therapy. Within each of these groups of nine, three had been taking a drug called anxifree, three had been taking a drug called joyzepam, and three a placebo. These are listed under the variable drug. The outcome variable is mood.gain, which is a measure of improvement of mood over some time period. The complete data set is displayed below Table 2.1. You will have to use the scroll bar to see the entire data set.
| ID | drug | therapy | mood.gain |
|---|---|---|---|
| 1 | placebo | no.therapy | 0.5 |
| 2 | placebo | no.therapy | 0.3 |
| 3 | placebo | no.therapy | 0.1 |
| 4 | anxifree | no.therapy | 0.6 |
| 5 | anxifree | no.therapy | 0.4 |
| 6 | anxifree | no.therapy | 0.2 |
| 7 | joyzepam | no.therapy | 1.4 |
| 8 | joyzepam | no.therapy | 1.7 |
| 9 | joyzepam | no.therapy | 1.3 |
| 10 | placebo | CBT | 0.6 |
| 11 | placebo | CBT | 0.9 |
| 12 | placebo | CBT | 0.3 |
| 13 | anxifree | CBT | 1.1 |
| 14 | anxifree | CBT | 0.8 |
| 15 | anxifree | CBT | 1.2 |
| 16 | joyzepam | CBT | 1.8 |
| 17 | joyzepam | CBT | 1.3 |
| 18 | joyzepam | CBT | 1.4 |
Your task is to enter this data manually into a new spreadsheet in jamovi. You’ll need to assign levels to the numbers you use for the two nominal variables. Do not enter them as text.
First, open a new spreadsheet in jamovi by clicking (\(\equiv\)) > New. Then save it with a reasonable name, like P301.Exercise_2.8.1.omv.
2.8.1.2 The ID variable
Second, double-click on the variable named A, and change the name to ID. You can provide a description if you like (this is good for remembering what your variables mean). Click ID as the variable type, and leave the box below that as Integer. Finally, type in 1-18 in the first 18 rows, respectively. You should have something like the results depicted in Figure 2.18, below.
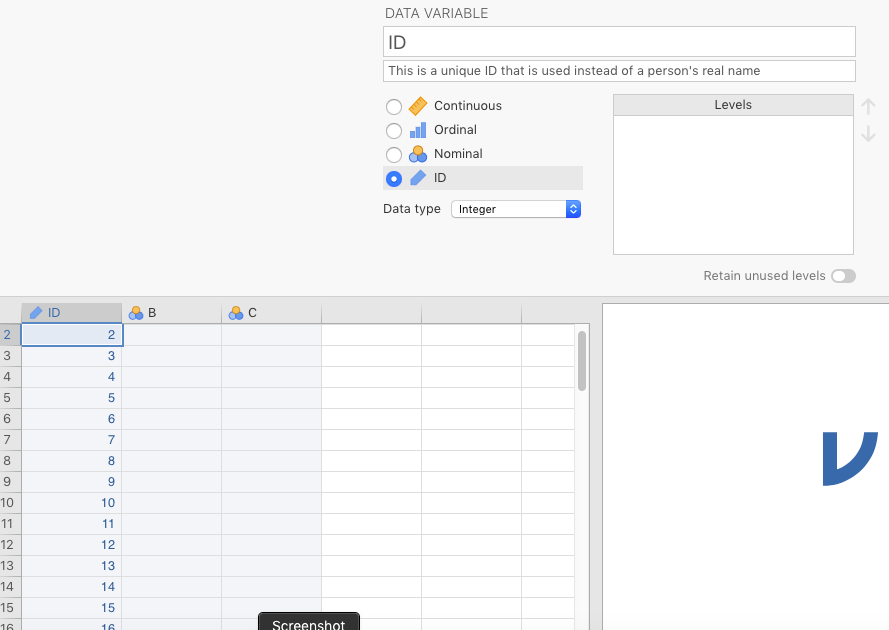
Figure 2.18: Entering an ID variable.
2.8.1.3 The drug variable
Third, prepare the variable drug with its three levels: anxifree, joyzepam, and placebo. Do this by double-clicking on the default variable B, and renaming it drug. The data type should remain nominal. Associate each of the levels of the drug variable with an integer, associations that will be arbitrary. We have chosen 0 for placebo, 1 for anxifree, and 2 for joyzepam (but you can use whatever integers to refer to whatever levels you like, as long as you don’t repeat them within the same variable). Then, for the first three rows (IDs 1-3) under drug, type in 0; for IDs 4-6 type in 1; and for IDs 7-9, type in 2. You should see something like Figure 2.19 below.
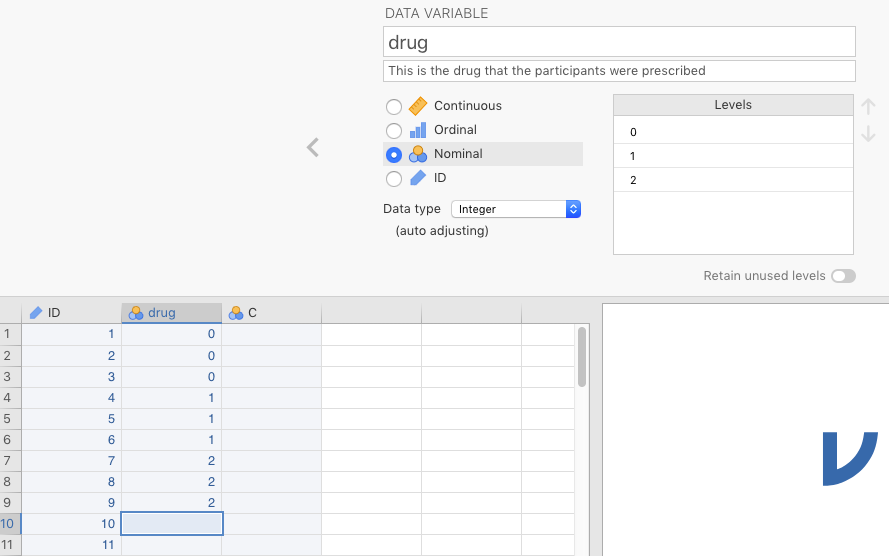
Figure 2.19: Entering the drug variable.
Once you have done this, you can replace the numbers in the Levels box with the names of the levels. Start with selecting 0, and typing over it with placebo. After this first step, you should see something like Figure 2.20 below.
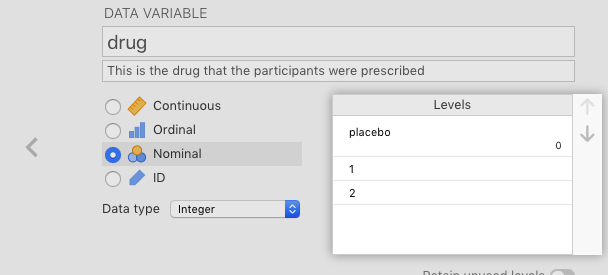
Figure 2.20: Start assigning labels to integer levels in a nominal variable.
Then, change overwrite 1 with anxifree and 2 with joyzepam. Click anywhere in the spreadsheet and you should see all the numbers disappear, replaced by the appropriate levels. Your results should look like what’s depicted in Figure 2.21.
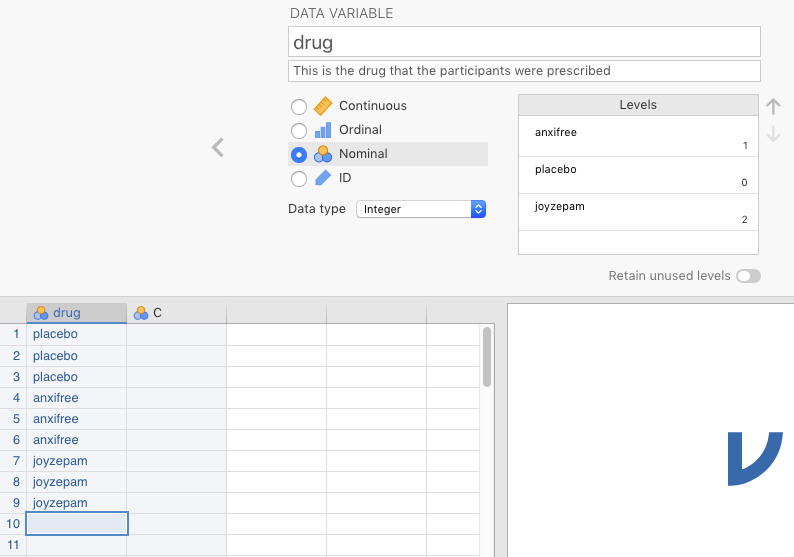
Figure 2.21: Complete assigning labels to integer levels in a nominal variable.
The last thing you need to do for the variable drug is type in the last nine integer values under drug (do not type in labels at this point). In this case, the same sequence of integers is repeated as above: that is, three 0s, followed by three 1s, and then three 2s. As you do this, you should see the labels fill in automatically, as in Figure 2.22 below.
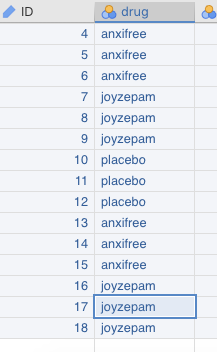
Figure 2.22: Fill in the rest of the values under the variable.
2.8.1.4 The therapy variable
Fourth, prepare the variable therapy. This is another nominal variable. There are two levels for the variable: no.therapy and CBT (which stands for Cognitive Behavioral Therapy). We will leave doing this to you since it is straightforwardly the same procedure as for drug, above. But pay close attention to Table 2.1.
2.8.1.5 The mood.gain variable
Fifth, you need to enter the data for mood.gain. When you click this fourth, blank column, a little menu with three options will appear (jamovi only provides you with 3 default variables). Choose NEW DATA VARIABLE. Rename D (or whatever letter you get there) with mood.gain. Then click the Continuous button, because this variable is going to be on an interval scale. Under the Data type pull-down menu, switch the variable from Integer to Decimal. At this point, you can just enter the data. Do so carefully, however, as the data are different for each row. And double-check your work. When you’re finished, you should see something like what’s depicted in Figure 2.23 below.
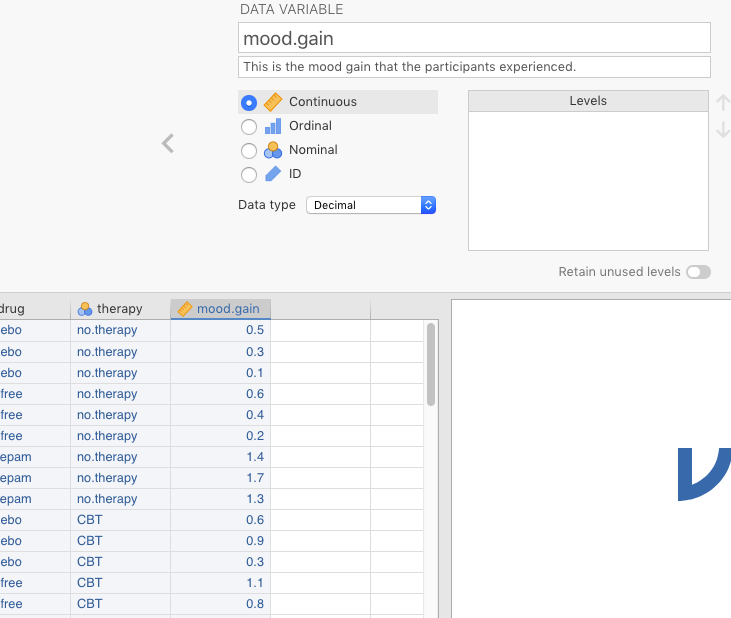
Figure 2.23: Entering the mood.gain variable manually.
You’re done!! with Practice Exercise @ref(#PracManualing)
Next you will work on importing and exporting data, but in reverse order. That is, we are first going to export data from a spreadsheet, which corresponds above to section 2.4 Then we will work on importing the data we just exported, which is covered above in Section 2.3.
2.8.2 Practice exporting
Here is some practice on Exporting, Practice Exercise 2B, starting with entering data into a spreadsheet.
2.8.2.1 Spreadsheet data
A great many researchers end up with their data stored somehow in a spreadsheet. This is not ideal, but it is very common. However, spreadsheets are not very powerful at statistics. For this reason, it’s usually best to export whatever data is in the spreadsheet into a delimited text file for subsequent import into statistics software like jamovi.36
So to mimic this all-too-common experience, you need to open up a spreadsheet in Google Sheets. The link takes you to Google Docs which includes Google Sheets. Note, you will need to create a Google account if you do not have one already. If you are a student at Texas A&M, you already have this, and we require you to use your university Google account. You can find it here, where you log in to Google Drive.
Under Drive in the upper left, click the + New icon to create a new document in your drive, and select Google Sheets. You should see a new Google Sheet open up.37 You can change the name in the upper left from Untitled spreadsheet to something like PracticeExportingDelimitedFiles (or something like that). Just click where it says Untitled Spreadsheet and type over it with the new name (e.g., Practice_Exercise_2.8.2. It’s automatically saved in your Google Drive.
In cell A1 (the upper-right-most cell in the grid), type ID. Move over one cell to the right (B1). Type in the name of some two-level nominal variable, like Sex (we’ll get to entering values below). Finally, in the third cell over (C1), type in the name of a continuous variable, like Aggression.
Let’s make 6 rows of data. For ID, type in 1-6 in cells A2 to A7, respectively. Under Sex type in a 1 in cells B2 to B4, and a 2 in cells B5 to B7. Under Aggression type in some random values on a scale from 1 to 7. See Figure 2.24 below for an example of how we did this.38
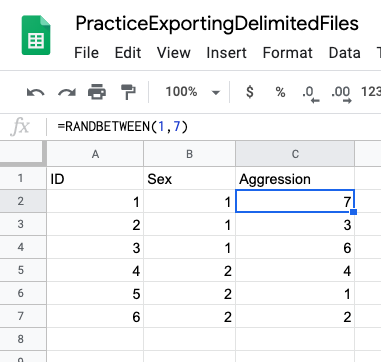
Figure 2.24: Entering data manually into Google Sheets.
2.8.2.2 Exporting to a delimited file
The next step is to export the data from the Google Sheet. This is extremely easy. Simply click File > Download as > Comma-separated values (.csv, current sheet). You can see an illustration of this below in Figure 2.25
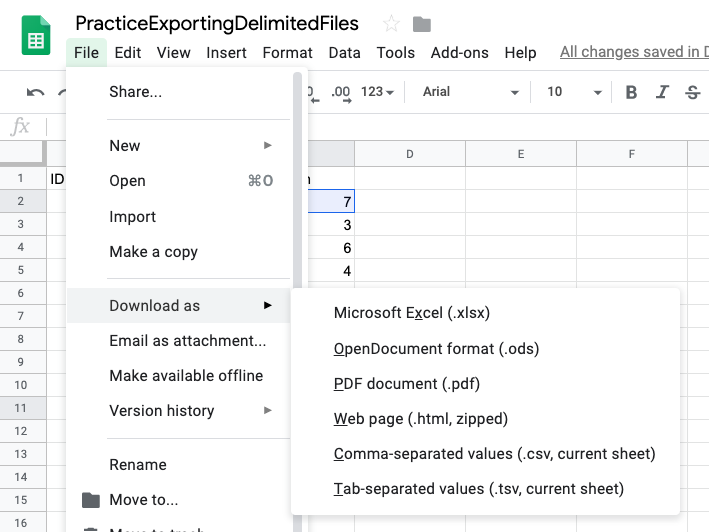
Figure 2.25: Exporting data into .csv format from Google Sheets.
Do this, and, when prompted, save it to somewhere on the same computer where jamovi is located. And remember where you saved it!
You could also bypass all this exporting from a spreadsheet program by just entering the data manually into a plain text file, and appending the appropriate file extension. No one does this, but it is useful for illustration. In fact, you can try this yourself by copying and pasting the text below into a program like TextEdit (on a Mac) or Notepad (on a PC), and saving it as a plain-text file with the appropriate file extension. Here is how you would do that (using TextEdit’s menu as the example [Notepad should be similar]):
- Select the four lines of text below, and then copy it to the clipboard:
"ID","Age","MaritalStatus"
"Bilbo",24,2
"Gandalf",32,1
"Boromir",44,1 - Open up TextEdit (or any other word processor)
- Paste the clipboard material in (you could also try typing it in directly)
- Go to
File>Save, give the file a name, and a.csvextension, and then clickSave
- Open up jamovi
- Go to (\(\equiv\)) >
Importand find the file you just created
This should work as well, though you can see why you’d have to be crazy to do it for large data sets.
2.8.3 Practice importing
Here is some practice on Importing, Exercise 2C: importing.
Open jamovi. Go to (\(\equiv\)) > Import. Once there, optionally select CSV at the bottom where it gives you a drop-down menu called Data files (this will narrow the file search). Click the Browse button at the upper right, and then search for your .csv file. You should see something like what’s in Figure 2.26.
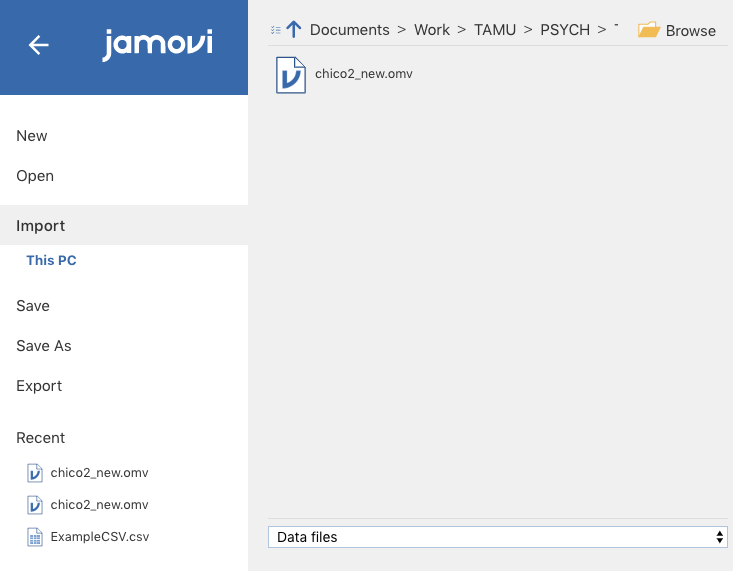
Figure 2.26: Starting to import a delimited file in jamovi.
Double-click it when you see it. You should see something like you see in Figure 2.27 below.
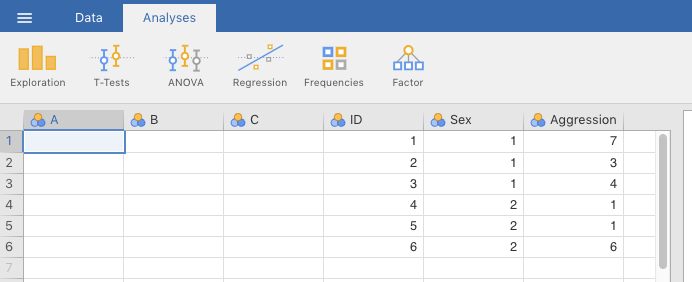
Figure 2.27: jamovi spreadsheet after importing delimited file.
Notice that jamovi just added the variables to the right of its default variables. Just delete the default variables by going to the Data tab at the top, selecting the column or any cell for variable A, and clicking the Delete icon in the menu at the top (the one with the vertical red stripe). Repeat this for variables B and C. Alternatively, you could select variable A, then hold down the SHIFT key, and select variable C. Then delete them all at once. This latter method was used in the screenshot depicted in Figure 2.28 below.39
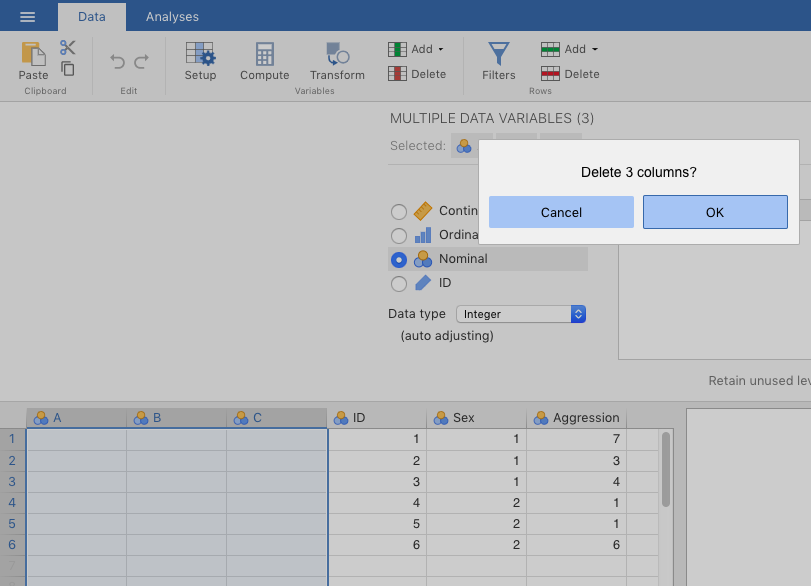
Figure 2.28: Deleting variables in jamovi.
In addition to adding unnecessary, default variables, jamovi also doesn’t recognize certain things that are critical to your analysis. It actually has no way of knowing the following, so it’s understandable:
IDshould be an ID variable, where the numbers should not be math-ed upon (it isNOTthe end of the world if this doesn’t get changed, as long as you know to ignore any statistics that get calculated from it);
- the numbers (
1and2) for forSexshould represent levels of a nominal variable (it couldn’t have since the levels were never assigned); and
Aggressionshould be continuous.
You just change these manually. Double-click ID and then click the ID option. Use the same procedure for Sex as you did in Sections 2.8.1.3 and 2.8.1.4, but assign, say 1 to Female and 2 to Male (or vice-versa; your choice). For Aggression use the same procedure you used in Section 2.8.1.5. That is, just change the variable type to Continuous. Keep the Data type as Integer (or make it so).
Make sure to save your results.
Congratulations! You’re done
References
In some cases, presumably, data might be collected on paper, and have to be entered manually. And there might be people digitizing certain, important data from analog to digital for archiving purposes. But overall, these sorts of tasks are rare nowadays in psychology.↩︎
.omvbeing the native file extension for jamovi files↩︎You might have noticed (or eventually notice) that some researchers (like me) use underscores (_) instead of blank spaces in variable names (periods are also common). This is because in many statistical programming languages like R, spaces in variable names can be problematic and cause errors. You can use spaces in jamovi though, and it works out better for graphics. Just don’t use too many words.↩︎
Yes, we reversed them from how they were described above, just to show you that the number-label associations are wholly arbitrary↩︎
Nor are SPSS, SAS, Stata, R, or any data-analysis software, with the two notable exceptions of MATLAB and Python, which can be used to write programs that collect data.↩︎
Yes, that’s the weirdest file extension in the history of computers.↩︎
You can’t see the tabs because tabs aren’t normally meant to be seen by computer users, but rest assured: they’re there.↩︎
The pipe is the \((\mid)\) character, which is on the same key as the backslash \((\backslash)\). This key is located above your computer’s enter/return key and below the delete/backspace key at the upper-right of the QWERTY keyboard layout (the default in the US)↩︎
Another common reason is if you want to create a new variable that is the sum or average of two or more other variables.↩︎
Pardon the apparent sexism. There seems to be no way to say this without making it sound like socio-economic status (e.g., “Upperclassperson”)↩︎
This is very common. Microsoft Excel also allows you to do this. In fact, the syntax is identical in Excel as the form is nearly universal.↩︎
This is to check for errors in the code. The word error should not appear in the results.↩︎
Actually, in many cases, like the current one as well as in Excel, there is no explicit else statement; it’s simply understood as the last argument in the series.↩︎
This might be slightly confusing, but the normality assumption, the assumption of a normal distribution, is not technically about the outcome variable itself, but rather about the residuals/deviations that are left over after a statistical model has been applied.↩︎
… or a square-root transformation, or a reciprocal transformation. In fact, there are several options available↩︎
courtesy of the R package trimr.↩︎
You will also see
LNthere, which is a natural-log transformation, where the base isn’t 10, but rather Euler’s number e, or 2.718281… To be sure, the natural log has special mathematical properties, which you can read about here, but we have never seen it make a difference in the log transformations of reaction-time data.↩︎Nothing is ever perfect in statistics, but close is often good enough.↩︎
Well, maybe a little.↩︎
Technically, the area below a normal curve at and beyond a z-score of +2 is 2.275%. We often use a z-score of 2 as a cutoff since it is easier than remembering 1.96, which is the z-score beyond which 2.5% of the observations should occur under a normal distribution. Multiplied by 2 for the two sides of the distribution, this comes to 5% of the data. The same is true of using a z-score of 2.5. It is easier than remembering 2.58, which, if used as a cutoff, will cut off 1% of the data (only 0.5% of the scores lie beyond 2.58 standard deviations above the mean; multiplied by two equals 1%). Ultimately, cutting off 5% or 1% of the extreme values using z-scores of 1.96 and 2.58, respectively, is really just as arbitrary as using z-scores of 2 and 2.5 to cut off 4.55% or 1.242% of the data, respectively. The results are really just about the same anyway. It’s just easier to remember 2 and 2.5 than 1.96 and 2.58.↩︎
Spreadsheets like Microsoft Excel do not do this necessarily, which is one reason why they can be so dangerous for data analysis. This deficiency is exactly what caused the “Excel error heard around the world.” (you can google that phrase)↩︎
Note that this is not true for spreadsheets like Microsoft Excel and Google Sheets. Spreadsheet programs like Lotus 1-2-3 were originally designed for accountants, and because of that, they offer so much flexibility and power that proper data storage and statistical analysis can quickly become problematic. Spreadsheets also astoundingly opaque when you share it with someone else (it’s notoriously difficult to unpack a developed spreadsheet without guidance from its creator). Nonetheless, because of their apparent simplicity and rapid learning curve, many people use spreadsheets to store data, and even analyze it there. One humorous/not-so-humorous example of a major mistake using spreadsheets was the “Excel Error Heard around the World,” (Google this) caught in 2013 by the (at-the-time) 28-year-old Thomas Herndon. That said, spreadsheets can be useful for some things in data analysis, but one must be extremely careful. A better alternative is usually a delimited-file editor like Comma Chameleon↩︎
It’s not usually recommended nowadays to use the singular form for data (lest you sound pedantic or ostentatious, since it really has fallen out of normal usage), but in this case it’s justified.↩︎
This practice is possible, but generally frowned upon since it necessarily involves the loss of information.↩︎
jamovi itself will also export data into different formats (as long as it has some data). To do this go to (\(\equiv\)) >
Export. There are both proprietary (e.g., SPSS’.savformat) and delimited text formats (e.g.,.csv). We won’t be doing this in this class, but it may be useful when sharing your data with others who don’t use jamovi.↩︎It is essentially the same as Microsoft Excel (commercial) or Libre Office Calc (free), among others.↩︎
To do this in a non-thinking way, a function in Google Sheets called RANDBETWEEN was used. You can see this in the formula bar just above the column references. The exact function is
=RANDBETWEEN(1,7), which means: “Produce a random number (integer) between the values of 1 and 7.” It was then copy-and-pasted fromC2toC3throughC7.↩︎You can also do all this before importing the new data.↩︎