Chapter 8 Comparing several means
This chapter explains how to use jamovi to analyze a continuous outcome variable when it is split into three or more levels of a categorical predictor variable. It follows the main textbook (Navarro & Foxcroft, 2019, Chapter 13)
For example, you might analyze something like attitude towards increasing taxes to fund public education. And your participants might have been, say, Democrats, Republicans, and “Others.” In this case, you could look at their mean responses by group, and figure out if any of these means were significantly different from any of the others.
8.1 The One-Way ANOVA
Carrying out One-Way ANOVA is covered in your main textbook (Navarro & Foxcroft, 2019, sec. 13.1 to 13.7).
In this test, we are interested in whether three or more groups comprising independent observations differ with each on a single, continuous outcome variable.80
The F-test is the calculation of a particular kind of ratio, the F-ratio (unsurprisingly!). It is the ratio of between-subjects variance (Mean Squares Between) divided by the within-subjects variance (Mean Squares Within). Each of these, respectively, is the ratio of the Sum of Squares (between or within) divided by the degrees of freedom (between or within). Thus:
\[F= \frac{MeanSquares_{between}}{MeanSquares_{within}} = \frac{SumOfSquares_{betweeen}}{DegreesOfFreedom_{between}}\Bigg{/}\frac{SumOfSquares_{within}}{DegreesOfFreedom_{within}}\]
And this is a pretty complex formula if spelled out all the way. You can refer to Table 13.1 in (Navarro & Foxcroft, 2019, p. 334) if you want to see how this works. In fact, Table 13.1 is in a standard ANOVA-table format, though we won’t go into that in this manual.
Naturally, you do not need to calculate the F-ratio by hand. jamovi will do it for you.
8.1.1 Basic: Clinical Trial data
The data set that Navarro and Foxcroft (2019) use to illustrate the One-Way ANOVA is fictional. It is a hypothetical clinical trial in which which 18 patients with moderate to severe depression are recruited to participate in a trial in which half receive Cognitive Behavioral Therapy in contrast to half who do not. Each half then receives one of three drugs: joyzepam, anxifree (a real antidepressant), and a placebo. Three participants are in each group, across both levels of therapy type (though therapy type is not analyzed here, though it is in Chapter 9). Their mood is measured at the beginning and then 3 months later on a 10-point scale from -5 to 5.
This lab manual simply presents the dataset and analysis in a more lab-like way.
8.1.1.1 Obtaining the data
To follow along yourself, you can open the in the module from Navarro & Foxcroft (2019): (\(\equiv\)) > File > Data Library > learning statistics with jamovi > Clinical Trial.omv. As noted above, we are only going to look at the effect of drug on mood.gain (the outcome variable); we will ignore the therapy variable for now.
8.1.1.2 Implementing the procedure
Simply click the Analyses tab and select ANOVA. Choose the ANOVA option there too (skipping over the One Way option as that is more limited).
When the options window opens, slide mood.gain into the Dependent Variables box, and drug into the Fixed Factors box.
Under Effect Size, click either \(\eta^2\) or partial \(\eta^2\) (which are identical in a One-Way ANOVA).
See Figure 8.1 directly below for a depiction of these options.
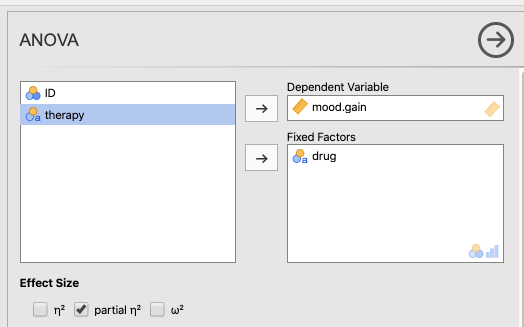
Figure 8.1: Main parameter settings for the ANOVA procedure using the Clinical Trial data from Navarro & Foxcroft (2019).
Next, click the arrow pointing to Model and make sure that drug is placed under Model Terms (and leave Sum of squares as Type 3.
There is no built-in correction for heterogeneous variances in this procedure, but you can test the assumption using Levene’s Test for Homogeneity of Variance. This avails itself if you check the box Homogeneity tests under Assumption Checks. See Figure 8.2 below for a depiction of these options.
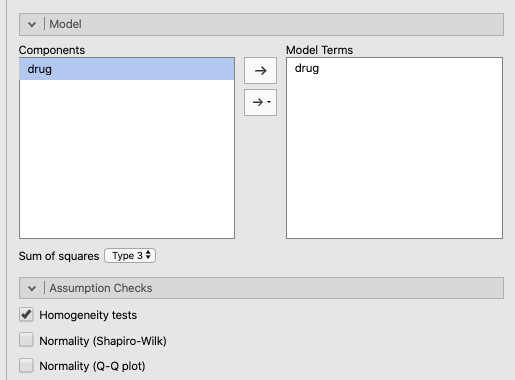
Figure 8.2: Model settings and assumption checks for the ANOVA procedure using the Clinical Trial data from Navarro & Foxcroft (2019).
Under Post-Hoc Tests, make sure that drug is in the box on the right, and that the Correction is set to Holm. This is a more powerful way to conduct multiple post-hoc analyses than Bonferroni adjustments (see Navarro and Foxcroft (2019, sec. 13.5.4, pp. 343-344) for a more thorough explanation). Scheffé and Tukey are also reasonable options. Ultimately however, all choices end up leading to the same conclusion in this case, which is often the case. See Figure 8.3 below for how to select these options.
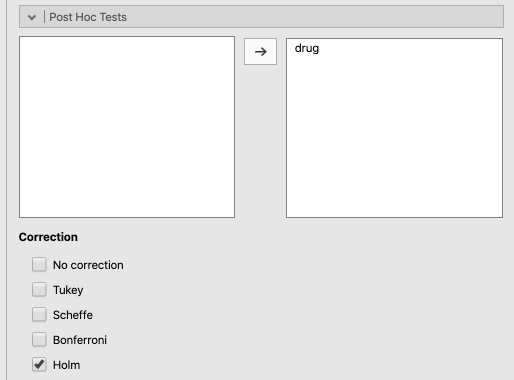
Figure 8.3: Multiple-comparison, post-hoc settings for the ANOVA procedure using the Clinical Trial data from Navarro & Foxcroft (2019).
Finally, under Estimated Marginal Means, make sure that the following are true:
drugmakes it over to the box on the right underTerm 1
- both boxes are checked under
Output(Marginal means plotsandMarginal means tables)
Equal cell weightsis checked (the default)
Error bars(underPlot) is set toConfidence interval
- and for fun, check the box
Observed scores.
These options are shown in Figure 8.4 below.
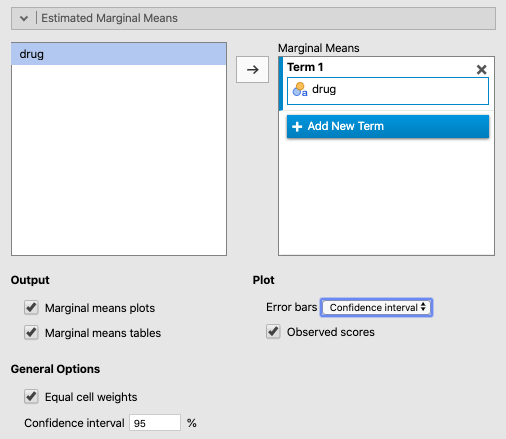
Figure 8.4: Graphic settings for the ANOVA procedure using the Clinical Trial data from Navarro & Foxcroft (2019).
The results should appear as follows:81
ANOVA
ANOVA - mood.gain
──────────────────────────────────────────────────────────────────────────────────────────
Sum of Squares df Mean Square F p η²p
──────────────────────────────────────────────────────────────────────────────────────────
drug 3.453333 2 1.72666667 18.61078 0.0000865 0.7127623
Residuals 1.391667 15 0.09277778
──────────────────────────────────────────────────────────────────────────────────────────
ASSUMPTION CHECKS
Homogeneity of Variances Test (Levene's)
────────────────────────────────────────
F df1 df2 p
────────────────────────────────────────
1.449739 2 15 0.2656941
────────────────────────────────────────
POST HOC TESTS
Post Hoc Comparisons - drug
───────────────────────────────────────────────────────────────────────────────────────────────────
drug drug Mean Difference SE df t p-holm
───────────────────────────────────────────────────────────────────────────────────────────────────
anxifree - joyzepam -0.7666667 0.1758577 15.00000 -4.359586 0.0011211
- placebo 0.2666667 0.1758577 15.00000 1.516378 0.1502131
joyzepam - placebo 1.0333333 0.1758577 15.00000 5.875963 0.0000914
───────────────────────────────────────────────────────────────────────────────────────────────────
Note. Comparisons are based on estimated marginal means
ESTIMATED MARGINAL MEANS
DRUG
Estimated Marginal Means - drug
────────────────────────────────────────────────────────────────
drug Mean SE Lower Upper
────────────────────────────────────────────────────────────────
anxifree 0.7166667 0.1243502 0.4516206 0.9817128
joyzepam 1.4833333 0.1243502 1.2182872 1.7483794
placebo 0.4500000 0.1243502 0.1849539 0.7150461
──────────────────────────────────────────────────────────────── 
The results should appear as follows:82
ANOVA
ANOVA - mood.gain
──────────────────────────────────────────────────────────────────────────────────────────
Sum of Squares df Mean Square F p η²p
──────────────────────────────────────────────────────────────────────────────────────────
drug 3.453333 2 1.72666667 18.61078 0.0000865 0.7127623
Residuals 1.391667 15 0.09277778
──────────────────────────────────────────────────────────────────────────────────────────
ASSUMPTION CHECKS
Homogeneity of Variances Test (Levene's)
────────────────────────────────────────
F df1 df2 p
────────────────────────────────────────
1.449739 2 15 0.2656941
────────────────────────────────────────
POST HOC TESTS
Post Hoc Comparisons - drug
───────────────────────────────────────────────────────────────────────────────────────────────────
drug drug Mean Difference SE df t p-holm
───────────────────────────────────────────────────────────────────────────────────────────────────
anxifree - joyzepam -0.7666667 0.1758577 15.00000 -4.359586 0.0011211
- placebo 0.2666667 0.1758577 15.00000 1.516378 0.1502131
joyzepam - placebo 1.0333333 0.1758577 15.00000 5.875963 0.0000914
───────────────────────────────────────────────────────────────────────────────────────────────────
Note. Comparisons are based on estimated marginal means
ESTIMATED MARGINAL MEANS
DRUG
Estimated Marginal Means - drug
────────────────────────────────────────────────────────────────
drug Mean SE Lower Upper
────────────────────────────────────────────────────────────────
anxifree 0.7166667 0.1243502 0.4516206 0.9817128
joyzepam 1.4833333 0.1243502 1.2182872 1.7483794
placebo 0.4500000 0.1243502 0.1849539 0.7150461
──────────────────────────────────────────────────────────────── 
8.1.1.3 Interpreting the output
The first thing to notice is actually the second table down. For Levene’s test of Homogeneity of Variance, the null hypothesis is that the distributions of the variables is equal across groups (the assumption itself). Therefore, you want to fail to reject the null hypothesis, which is what happened here as p = .266. This also means that there is no problem interpreting the table above it, which is covered next.
The second thing to notice is the table at the top. This is known as an ANOVA table. It has a very specific structure. The key value is the p-value in the second-to-last column. It is below .05, so you can reject the null hypothesis that the three drugs have an equal effect on patients. How to report the F-test in APA format is covered below in section 8.1.1.4.
However, another key value is in the last column. This is the effect size, \(\eta_p^2\). This statistic is also a bit redundant in the table since it is actually derived from column two. Well, when there is one predictor variable, it is equivalent to \(\eta^2\) (eta squared), which is available from the table as the sum of squares between divided by the total sum of squares. The effect size here of .713 is quite large.
\[\eta^2 = \frac{SumOfSquares_{between}}{SumOfSquares_{total}}= \frac{SumOfSquares_{between}}{SumOfSquares_{between}+SumOfSquares_{within}}=\] \[\frac{3.45}{3.45+1.39} = \frac{3.45}{4.84} = 0.713\]
Naturally, that F-test is an omnibus test, and only tells us that there are some significant differences among the three means, but it doesn’t tell us which. Therefore, there are also some post-hoc tests that we called for, which are located in third table down. It appears that there is a significant difference between joyzepam and each of the other two drugs, but not between the other two drugs themselves. This is clear in the figure, where you can see that the confidence interval for joyzepam does not overlap with either of the other two drugs, but the confidence intervals of the other two drugs overlap with each other quite a bit.83
Also note that the Estimated Marginal Means may be slightly different than the means that you obtain from running Exploration > Descriptives in jamovi. This topic is beyond the scope of this class as it has to do with how means are calculated multiple regression. Although these are legitimate estimates, you should report the means and standard deviations from the Descriptives procedure instead of the Estimated Marginal Means from the ANOVA output.
8.1.1.4 Reporting the output
As already shown in the case of chi-square, the z- and t-tests, and the correlation/regression chapter, APA requires a consistent pattern for reporting statistical output:
- a letter (in italics) representing the test statistic used
- parentheses that enclose the degrees of freedom
- an equals sign
- the obtained value of the test statistic
- a comma
- the letter p in italics
- one of three symbols: =, <, or >
- a p-value
There will be only two differences this time:
- The test letter is now F (not t or \(\chi^2\))
- There are two degrees of freedom instead of one
To report the F-test in APA format, you can get all the information you need from the second table in the output above (the ANOVA table). The test statistic is F. There are two degrees of freedom: one for the sum of squares between, and one for the sum of squares within. These are located in the third column under df. They are 2 an 15, respectively, in that order [i.e., (\(df_{between}\),\(df_{within}\))]. Next, we need the F-ratio itself, which is located in the fifth column under F. As noted above, the p-value is in the second-to-last column. We also report the effect size, which is in the last column. All together, the full report of the test statistic, in the order presented directly above, is as follows:
\(F(2,15)=18.6,p<.001, \eta_p^2=0.713\)
We can now put together a partial Results section for this one analysis:
The mood improvement over the course of three months differed significantly across the three groups of patients taking either joyzepam, anxifree, or a placebo, \(F(2,15)=18.6,p<.001, \eta_p^2=0.713\). Post-hoc comparisons with Holm corrections revealed that there was a significant difference between joyzepam (M = 1.48, SD = 0.214) and both anxifree (M = 0.717, SD = 0.392), \(t(15)=-4.36,p<.001\), and the placebo (M = 0.45, SD = 0.281), \(t(15)=5.88,p<.001\). However, there was no significant difference between anxifree and the placebo, \(t(15)=1.52,p=.15\). These differences are also clear in Figure 1, where it is clear that the 95% confidence interval for joyzepam does not overlap with those of either of the other two conditions, whereas the confidence intervals for the latter two conditions overlap substantially. joyzepam is clearly resulting in a significantly greater mood gain than the other two conditions. Additionally, the effect size (\(\eta^2=0.713\)) is quite large, suggesting that this difference between joyzepam and the other two conditions is quite substantial in magnitude.
References
Technically, you can also do this kind of test on a categorical variable with only two levels, something you would normally think to do an independent-samples t-test on. However, the results will be the same in this case, except that the ultimate obtained value for F (the ANOVA test) will be the equivalent of the obtained value for t, but squared. (Navarro & Foxcroft, 2019) talk about this briefly in section 13.10.↩︎
Recall that the output below (and further down) was generated from the jmv package in R, and will therefore be rounded to more decimal places than the native output in jamovi.↩︎
Recall that the output below was generated from the jmv package in R, and will therefore be rounded to more decimal places than the native output in jamovi.↩︎
Note that this is an approximate rule. Sometimes confidence intervals do overlap a little between variables that turn out to be significantly different.↩︎